Cost-Effective Large Language Model Benchmarking
Benchmark LLMs with H100 GPUs in parallel for under $3 per run, thanks to serverless magic!
In this tutorial, we'll demonstrate how to benchmark large language models (LLMs) using Covalent Cloud, leveraging its serverless capabilities to run benchmarks efficiently. By utilizing 20 H100 GPUs in parallel, we can execute LLMs as "batch" jobs, where each benchmark run on an H100 costs just under $3. This cost-effective approach is ideal for scenarios requiring intensive computations periodically or for specific tasks, without the overhead of maintaining always-on services. Covalent Cloud's infrastructure allows us to host, orchestrate, and execute multiple model evaluations in parallel, ensuring optimal use of computational resources.
From an infrastructure perspective, we will set up cloud executors to handle LLM hosting and orchestrate the benchmarking workflow, choosing the right hardware needed for various parts of the code. This includes deploying the models, running the tasks, and managing the compute resources dynamically to meet the demand. This example will highlight the flexibility and scalability of Covalent Cloud, allowing you to handle large-scale AI tasks efficiently.
Benchmarking Setup and Dataset
Specifically, we will benchmark the performance of Llama 3 8B on the GPQA (A Graduate-Level Google-Proof Q&A Benchmark) dataset. GPQA is a challenging dataset comprising 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. These questions are designed to be extremely difficult, with experts achieving only 65% accuracy on average and skilled non-experts reaching 34% accuracy even with unrestricted web access. This makes GPQA an excellent benchmark for evaluating the capabilities of LLMs in answering complex, high-quality questions. Given the complexity of the task, even state-of-the-art AI systems like GPT-4 have shown limited success, achieving only 39% accuracy. In this example, we will use the GPQA Diamond Set (198 Questions) for benchmarking.
By the end of this example, you will have learnt how to have a robust setup running LLM benchmarks, enabling you to assess and compare the performance of different models in a scalable and efficient manner.
Set up the LLM Service and Generation Functions
First, define the functions to serve the LLM and generate text based on prompts.
from dataclasses import dataclass, field
from typing import List, Optional, Union
import random
class Expert:
def __init__(self, model, prompt_template="", temperature=0.7, top_p=0.8, num_tokens=500,seed=None, **vllm_kwargs):
from vllm import LLM
if seed is None:
seed = random.randint(0, 1000000)
print(f"Setting seed to {seed}")
self.seed=seed
self.llm = LLM(model=model,seed=self.seed,trust_remote_code=True,enforce_eager=True, **vllm_kwargs)
self.prompt_template = prompt_template
self.temperature = temperature
self.top_p = top_p
self.num_tokens = num_tokens
def generate(self, prompt, schema=None):
from lmformatenforcer import JsonSchemaParser
from lmformatenforcer.integrations.vllm import (
build_vllm_logits_processor, build_vllm_token_enforcer_tokenizer_data)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature=self.temperature, top_p=self.top_p, max_tokens=self.num_tokens)
tokenizer_data = build_vllm_token_enforcer_tokenizer_data(self.llm)
if schema:
jsp = JsonSchemaParser(schema)
logits_processor = build_vllm_logits_processor(tokenizer_data, jsp)
sampling_params.logits_processors = [logits_processor]
results = self.llm.generate(prompt, sampling_params=sampling_params)
if isinstance(prompt, str):
return results[0].outputs[0].text
else:
return [result.outputs[0].text for result in results]
def answer_query(self, prompts, schema=None):
full_prompt = self.prompt_template.format(prompts=prompts)
return self.generate(prompt=full_prompt, schema=schema)
def process_questions(self, questions: Union[str, List[str]]):
if isinstance(questions, str):
questions = [questions]
results = [self.answer_query(question) for question in questions]
if len(results) == 1:
return results[0]
return results
Download and Process Questions
Download the dataset and process the questions to get answers from the LLM, for convenience, we have hosted the unzipped version of GPAQ dataset in this Github gist, which we will download and use in this example.
import csv
def get_row_from_csv(csv_file_path, row):
"""Get the nth row or all rows from a CSV file."""
with open(csv_file_path, 'r', encoding='utf-8') as file:
reader = csv.DictReader(file)
if row == 'all':
return list(reader)
else:
for i, current_row in enumerate(reader):
if i == row:
return current_row
return None
from dataclasses import dataclass
from typing import List
@dataclass
class QuestionData:
question: str
correct_answer: str
incorrect_answers: List[str]
explanation: str
formatted_question: str
def __str__(self):
return "\n".join(f"{key}: {value}" for key, value in self.__dict__.items())
def __repr__(self):
return self.__str__()
def format_question_from_row(row):
"""Format the row into a QuestionData dataclass."""
question_data = {
"question": row["Question"],
"correct_answer": row["Correct Answer"],
"incorrect_answers": [row["Incorrect Answer 1"], row["Incorrect Answer 2"], row["Incorrect Answer 3"]],
"explanation": row.get("Explanation", "No explanation provided")
}
options = question_data["incorrect_answers"]
options.insert(0, question_data["correct_answer"]) # Correct answer is always the first option (A)
formatted_options = "\n".join(
f"{chr(ord('A') + i)}. {option}" for i, option in enumerate(options)
)
formatted_question = f"{question_data['question']}\nPick an answer from the following options: \n{formatted_options}\nPlease first provide your reasoning, then answer with a single letter choice formatted as 'The answer is X.'"
return QuestionData(
question=question_data['question'], # nice to have
correct_answer=question_data['correct_answer'], # nice to have
incorrect_answers="None", # Not needed for this use case
explanation="None", # Not needed for this use case
formatted_question=formatted_question
)
import json
import requests
import csv
import io
def download_file(url):
"""Download a file from a URL and return the local file path."""
local_filename = url.split('/')[-1]
response = requests.get(url)
with open(local_filename, 'wb') as f:
f.write(response.content)
return local_filename
Evaluate the accuracy
We use bart model to extract the choice using it in zero shot classification mode. This is necessary because LLMs, even when fine-tuned, might not always provide clear, direct answers to multiple-choice questions. The BART model helps to extract the most probable answer choice from the generated text, improving the accuracy and reliability of our evaluation. Note that there are other ways to evaluate the generated text, such as using a separate model or a rule-based system, but we will use BART for simplicity (although this is one of the most effective methods).
Submiting it to Covalent Cloud
Covalent Cloud provides several primitives that make it easy to create, deploy, and manage complex workflows involving large language models. Here, we will explain some of the key concepts and components you'll use to submit the benchmarking workflow.
- Environment Creation: - Use
cc.create_envto create a new environment with the necessary dependencies for the benchmarking task. - Electrons (tasks) -
@ct.electrondecorators, turn a function into a task that can be executed on the cloud with the specified resources. - Lattice (workflows) -
@ct.latticedecorators, define a workflow that orchestrates the execution of multiple tasks. You can specify the dependencies between tasks and the resources required for each task just as a normal python function. - Executor - Use
cc.CloudExecutorto define the computational resources used to run your tasks. You can specify the number of CPUs, amount of memory, type and number of GPUs, and time limits for your tasks.
import covalent_cloud as cc
import covalent as ct
cc.save_api_key("your_api_key_here")
cc.create_env("gpqa-benchmark",pip=["vllm==0.5.1","huggingface-hub","transformers","torch==2.3.0","sentencepiece","sentence-transformers"], wait=True)
num_gpus=1
gpu = cc.CloudExecutor(
env="gpqa-benchmark",
num_cpus=4,
num_gpus=num_gpus,
memory="100GB",
gpu_type=cc.cloud_executor.GPU_TYPE.H100,
time_limit="1 hours",
)
cpu=cc.CloudExecutor(
env="gpqa-benchmark",
num_cpus=4,
memory="50GB",
)
high_cpu=cc.CloudExecutor(
env="gpqa-benchmark",
num_cpus=12,
memory="80GB",
)
@ct.electron(executor=gpu)
def get_answers(url,model,prompt_template,batch_size=1):
file_name=download_file(url)
expert = Expert(model=model, prompt_template=prompt_template,temperature=.8, top_p=.8, num_tokens=500)
row_text = get_row_from_csv(file_name, row='all')
question= [format_question_from_row(i) for i in row_text]
question_batch=[question[x:x+batch_size] for x in range(0, len(question), batch_size)]
answered_questions=[]
for i in question_batch:
question_text=[j.formatted_question for j in i]
answers=expert.process_questions(question_text)
if isinstance(answers,str):
answers=[answers]
for j,answer in enumerate(answers):
i[j].model_answer=answer
print(f"Question: {i[j].question}\nModel Answer: {i[j].model_answer}\nCorrect Answer: {i[j].correct_answer}\nExplanation: {i[j].explanation}\n")
answered_questions.extend(i)
return answered_questions
@ct.electron(executor=high_cpu)
def classify_answer(answers, model_name="facebook/bart-large-mnli"):
from transformers import pipeline
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model=model_name)
new_answers = []
for i in answers:
labels = ["A", "B", "C", "D", "Unknown"]
best_label = classifier(i.model_answer, candidate_labels=labels)['labels'][0]
i.model_answer_choice = best_label
new_answers.append(i)
return new_answers
@ct.lattice(executor=gpu,workflow_executor=cpu)
def gpqa_benchmark(url,model,prompt_template,model_classify="facebook/bart-large-mnli",batch_size=1,n_runs=1):
runs=[]
for _ in range(n_runs):
answers=get_answers(url=url,model=model,prompt_template=prompt_template,batch_size=batch_size)
runs.append(classify_answer(answers,model_name=model_classify))
return runs
We will dispatch all these workflows in parallel. As this is just a demonstration, we have not put all the bells and whistles in the code to take care of stochasticity associated with answers and other factors, Hence some of the runs might fail, which can be avoided by adding try-except blocks and retrying the failed runs. Nonetheless, this example will give you a good starting point to build a robust benchmarking setup for LLMs.
from IPython.display import clear_output
def submit_jobs(dataset_url, models_prompts, batch_size=1, n_runs=1):
run_ids_dict = {}
for model, prompt_template in models_prompts.items():
run_ids = []
for _ in range(n_runs):
runid = cc.dispatch(gpqa_benchmark)(
url=dataset_url,
model=model,
prompt_template=prompt_template,
model_classify="facebook/bart-large-mnli",
batch_size=batch_size,
n_runs=1
)
run_ids.append(runid)
clear_output(wait=True)
run_ids_dict[model] = run_ids
return run_ids_dict
# Define the dataset URL
dataset_url = "https://gist.githubusercontent.com/santoshkumarradha/d0df4d442b98d7b70b1443243a17af59/raw/37a954c5a7f45e11056f20f4aeec6f35a69c3675/gpqa_diamond.csv"
models_prompts = {
"unsloth/llama-3-8b-Instruct": """<|begin_of_text|><|start_header_id|>system<|end_header_id|>You are an helpful assistant who will answer the multiple choice question in hand and pick a choice between A,B,C,D. Keep the answer short<|eot_id|><|start_header_id|>user<|end_header_id|> {prompts}. keep the answer short<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
"microsoft/Phi-3-mini-4k-instruct": """<|user|>\nYou are an helpful assistant who will answer the multiple choice question in hand and pick a choice between A,B,C,D. Keep the answer short. \n {prompts} <|end|>\n<|assistant|>""",
}
# Submit jobs and get the run IDs
run_ids_dict = submit_jobs(dataset_url, models_prompts,n_runs=10)
# Print the run IDs
print(run_ids_dict)
Once dispatched, take a look at your Covalent Cloud Dashboard to monitor the progress of your workflow. You can view the logs, metrics, and results of each task, as well as the overall progress of the workflow.
We will wait here for the result, but you can also query the result with result id asynchrounously anytime using cc.get_result function. Note that the actual result values are always lazy-loaded, so you need to call .load() and then .value to get the actual result whenever you need. This is because, Covalent Cloud currently allows you to pass and return objects of size upto 5GB (Beyond that, feel free to use the shared volumes feature to store data and share/pass between tasks), which can be very large and can cause memory issues if loaded all at once.
final_results = {}
for model, run_ids in run_ids_dict.items():
results = []
for run_id in run_ids:
res=cc.get_result(run_id,wait=True) #waiting for jobs to be completed
if res.status=="COMPLETED":
res.result.load()
[results.append(i) for i in res.result.value]
final_results[model] = results
# Note that this run might have failed, please check the status of the run or choose a different run
print(final_results['unsloth/llama-3-8b-Instruct'][0][0])
question: Two quantum states with energies E1 and E2 have a lifetime of 10^-9 sec and 10^-8 sec, respectively. We want to clearly distinguish these two energy levels. Which one of the following options could be their energy difference so that they can be clearly resolved?
correct_answer: 10^-4 eV
incorrect_answers: None
explanation: None
formatted_question: Two quantum states with energies E1 and E2 have a lifetime of 10^-9 sec and 10^-8 sec, respectively. We want to clearly distinguish these two energy levels. Which one of the following options could be their energy difference so that they can be clearly resolved?
Pick an answer from the following options:
A. 10^-4 eV
B. 10^-11 eV
C. 10^-8 eV
D. 10^-9 eV
Please first provide your reasoning, then answer with a single letter choice formatted as 'The answer is X.'
model_answer:
To clearly distinguish between the two energy levels, the energy difference should be at least 10 times the linewidth, which is the reciprocal of the lifetime. The linewidth is proportional to the lifetime, so the energy difference should be at least 10 times the energy difference between the two states.
The energy difference between the two states is 10^-9 sec / 10^-8 sec = 0.1 eV. Therefore, the answer is:
The answer is A.
model_answer_choice: A
def analyze_results(result):
"""Analyze the answer extraction results and provide accuracy."""
correct_count = sum([1 for i in result if i.model_answer_choice=='A'])
accuracy = correct_count / len(result)
return accuracy
import numpy as np
accuracies={}
for model, result in final_results.items():
accuracy = [analyze_results(i) for i in result]
accuracies[model] = accuracy
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = []
for model, acc_list in accuracies.items():
for acc in acc_list:
data.append((model, acc))
df = pd.DataFrame(data, columns=['Model', 'Accuracy'])
fig, ax = plt.subplots(figsize=(10, 3))
sns.boxplot(y='Model', x='Accuracy', data=df, palette="pastel", ax=ax,hue='Model',legend=False)
sns.swarmplot(y='Model', x='Accuracy', data=df, palette='Set2', ax=ax,hue='Model',legend=False)
plt.title("Accuracy of Different Models on GPQA Benchmark", fontsize=13)
plt.xlabel("Accuracy", fontsize=10)
plt.ylabel("Model", fontsize=10)
plt.xlim(0, 1)
ax.set_xticks(np.arange(0, 1.01, 0.1))
ax.set_xticklabels([f"{int(i*100)}%" for i in ax.get_xticks()])
plt.tight_layout()
plt.show()
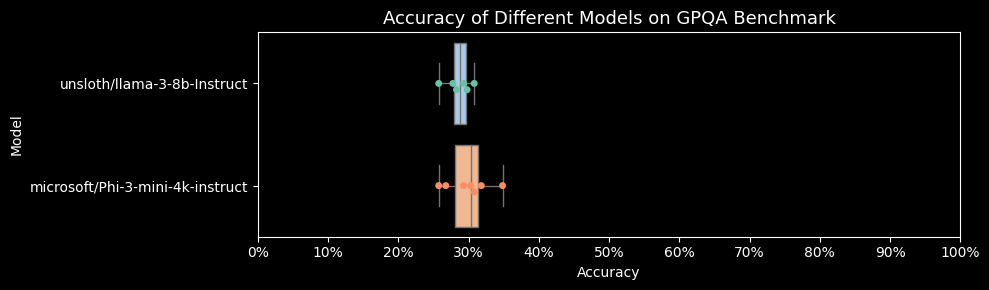
By running this experiment, you can efficiently benchmark multiple models across different iterations, leveraging Covalent Cloud's ability to execute tasks in parallel. This setup ensures that each experiment is isolated and can be run independently, making it ideal for large-scale benchmarking tasks. Best of all, you achieved all of this directly from Python without touching a single aspect of the infrastructure side. Additionally, integrating these compute workflows inside Github actions or any CI/CD pipeline allows you to automate these benchmarks routinely for all running models in production, as demonstrated in this Github Action Example.