GitHub Workflows Meets High-Performance Compute
⭐ Github Template Repo can be found here
GitHub Workflows excel at automating software development tasks. But what if you could effortlessly harness the power of high-performance computing (HPC) directly within these workflows? Imagine tackling computationally intensive tasks like scientific simulations, massive data analysis, and complex machine learning model training – all streamlined within your GitHub processes. This opens up a new realm of possibilities, allowing us to tackle computationally demanding tasks that were previously challenging or even impossible to include within automated processes, for example:
- Continuous Integration for High-Performance Code: Benchmark and optimize computationally intensive scientific code (e.g., simulations, numerical analysis) as part of your CI/CD pipelines, ensuring performance remains consistent as your codebase evolves.
- AI-Powered Code Enhancements: Integrate large language models (LLMs) or custom generative AI models into your workflows to suggest code improvements, refactor code for efficiency, or even assist in generating tests.
- Time-Based Monitoring and Analysis: Process and analyze massive datasets (e.g., climate data, financial markets, sensor networks) on a schedule or in response to real-time events. Trigger updates or alerts based on complex calculations performed within your workflows.
- Machine Learning Pipelines: Automate the training, hyperparameter tuning, and deployment of machine learning models. Leverage specialized hardware (GPUs) for accelerated training, directly accessible within the workflow.
Traditionally, achieving the power of high-performance computing (HPC) within workflows comes with a significant burden of infrastructure management. Setting up and maintaining specialized compute machines (often with GPUs or unique hardware) is complex and expensive, especially when considering cost-effectiveness. Additionally, relying on shared HPC resources often involves waiting in queues, hindering rapid experimentation and delaying workflows. Furthermore, building custom infrastructure to connect workflows with HPC results, track logs, and manage file storage adds another layer of complexity and overhead. These challenges create a barrier for developers who want to leverage the power of HPC within their automated workflows.
Covalent Cloud: The Serverless Compute Solution
Covalent Cloud addresses these challenges by offering a serverless platform for deploying high-compute functions. With a simple Python interface, developers can focus on their core computational logic while Covalent Cloud handles the following complexities:
- Resource Provisioning: Specify the required resources (CPU, GPU, memory) within your function, and Covalent Cloud allocates them on demand.
- Scaling: Functions scale automatically based on workload, ensuring optimal performance and cost-efficiency.
- Simplified Integration: Execute high-compute functions directly from your GitHub Workflows, retrieve results, and streamline workflow logic from environment setup for each tasks to logging.
A Flexible Template: Getting Started
To illustrate this powerful integration, we'll provide a GitHub template repo that dispatches dummy high-compute functions to Covalent Cloud as part of its workflow. This serves as a flexible foundation – you can easily replace the placeholders with your own intensive code.
Key Architectural Pattern: Asynchronous High-ComputeThe core of this template showcases a fundamental asynchronous architecture for integrating serverless high-performance computing within GitHub Workflows. Here's how it works:
- Job Submission:
Your workflow dispatches one or more computationally demanding tasks to Covalent Cloud, receiving unique
runIDs in return. These IDs are stored for tracking purposes. - Asynchronous Result Monitoring:
A separate part of the workflow periodically queries Covalent Cloud using the stored
runIDs. If a run is completed, its results are retrieved and made available for further use within the workflow logic.
For even greater flexibility, consider decoupling job submission and result monitoring into separate workflows. This allows for independent scheduling (e.g., infrequent submission vs. rapid result checking) and opens possibilities for more complex workflows.
Customization is Key:This template is a starting point.Adjust the workflow triggers, polling frequency, and logic to fully utilize this architecture for a variety of use cases.
Check out the GitHub Template Repo here: https://github.com/AgnostiqHQ/covalent-cloud-github-workflow for a hands-on exploration!
Project Structure
├── .github
│ └── workflows
│ ├── covalent_workflow.py # Your high-compute Python functions
│ ├── requirements.txt # Project dependencies
│ ├── script.py # Workflow dispatch and result handling script
│ ├── submit_and_update.yaml # GitHub Workflow definition
│ └── utils.py
├── results.csv # Stores results of completed runs
└── runid_status.csv # Tracks status of dispatched jobs
Understanding Covalent Primitives
Covalent provides a few key building blocks that make working with serverless high-performance computing incredibly straightforward:
- Electrons: Self-contained tasks and functions of your computationally intensive Python code. We call these tasks as electrons.
- Lattices: Blueprints that chain electrons together, defining your workflow or pipeline, including dependencies.
- Cloud Executor: Specifies the compute resources needed for each electron.
- Dispatch: Sends your workflow to Covalent Cloud for execution, returning a unique run ID for tracking.
GitHub Workflow Logic: Step-by-Step
- Workflow Trigger:
- The workflow is triggered by an event. You'll define this in the submit_and_update.yaml file (e.g., on a schedule, code push, or external webhook).
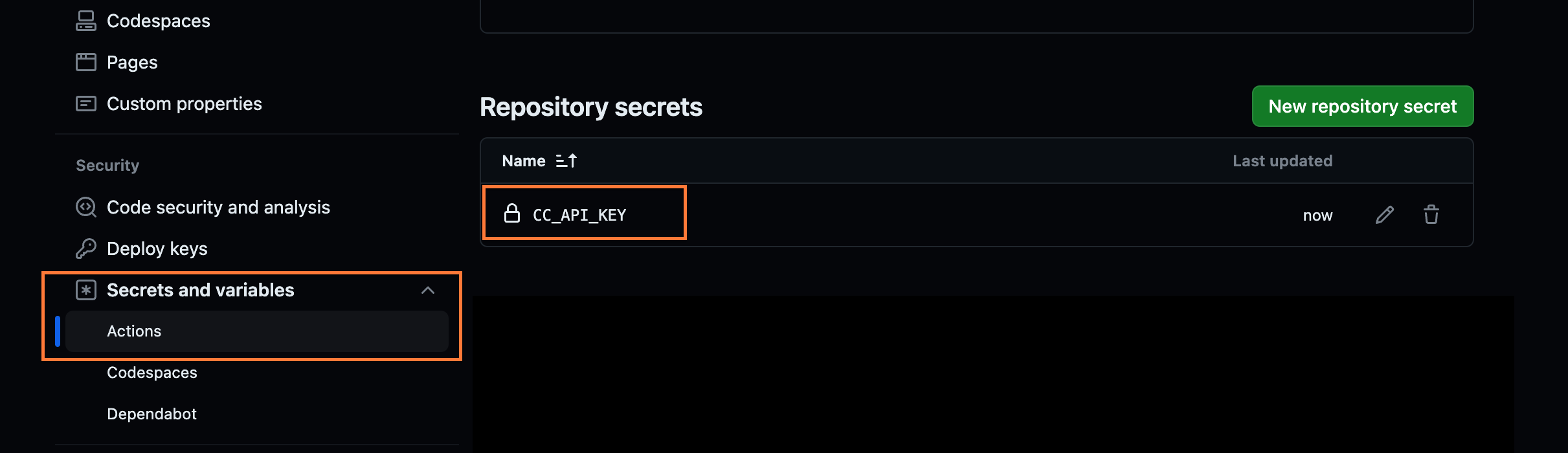
- Set Up Covalent API Key:
Before running the workflow, you must set your Covalent Cloud API Key as a GitHub secret named
CC_API_KEY.- This allows your workflow to authenticate with Covalent Cloud.
- Dispatch to Covalent:
- The script.py file executes. It dispatches the lattice (defined in covalent_workflow.py) to Covalent Cloud.
- The high-compute functions are sent to Covalent's servers for execution.
- Covalent Cloud returns a unique
runIDto identify this workflow execution.
- Store Run ID:
- The script.py stores the received
runIDin the runid_status.csv file, along with its initial status (e.g., "PENDING").
- The script.py stores the received
- Result Monitoring (Asynchronous):
- A separate job in submit_and_update.yaml periodically runs to check the status of previously dispatched jobs.
- It queries Covalent Cloud using the stored
runIDs. - Upon completion of a run, it retrieves the results and stores them in results.csv file.
- Git Commit:
- If changes have been made to the results.csv file or runid_status.csv file , the workflow commits and pushes these changes back to your GitHub repository. This effectively versions your computational parameters alongside your code modifications.
Customizing Your Workflow: Real-World Examples
The power of this template lies in its adaptability. Let's explore how you can modify different aspects to align with various high-compute use cases:
Triggers
- Scheduled Model Retraining: Run the workflow on a daily or weekly basis to retrain machine learning models with the latest data, ensuring they remain accurate.
- Code Change Triggered Simulation: If a code modification affects your scientific simulation parameters, automatically launch the workflow to re-run simulations and assess the impact of changes.
- Webhook-Based Analysis: Connect external systems (e.g., sensor data streams) to trigger the workflow when new data needs processing or analysis using high-performance resources.
Asynchronous Monitoring
- Adjust the frequency: For time-critical analyses, check on status updates more frequently; for longer-running computations, a less frequent polling interval might be suitable.
- Advanced Notifications: Build in custom notifications to alert you (via email, Slack, etc.) when specific runs complete or if results meet certain criteria.
Workflow Structure
- Separate Submission and Monitoring: Break down the workflow into dedicated jobs for submitting computations and handling result monitoring. This can enhance modularity and allow for independent scheduling.
- Complex Pipelines: Design multi-stage workflows where the output of one high-compute task triggers a subsequent one. Covalent's lattice structure supports defining these dependencies.
- Dynamic Resource Selection: Based on the task in hand dynamically select the executor parameters to decide on the fly where to send the tasks to.
- Efficient Re-Dispatches: With Covalent's re-dispatch feature, you can directly send existing workflows to Covalent Cloud. All you need is its
runidand new inputs. There's no need for the dispatching environment to have the same dependencies as the workflow.
The possibilities are truly vast! Remember, the example provided is a starting foundation. Feel free to tailor the triggers, frequency, and structure of your workflow to achieve complex and powerful automation
⭐ Github Template Repo can be found here