Building a Multi-Agent Prompt Refining Application
Welcome to this tutorial where we will build a sophisticated multi-agent application using Covalent Cloud, designed to iteratively refine prompts for large language models (LLMs) like GPT-4. Our goal is to create an application where multiple specialized agents, each made out of smaller models, work together to enhance the quality of input prompts. This is critical because we may not want to waste the compute time of large models with suboptimal prompts. By refining the prompt with cheaper, smaller models first, we can optimize the use of the more expensive, larger models.
The major benefit of working with Covalent Cloud is that with this notebook, we get a production ready prompt refining multi agent application that we can expose as scalable backend right out of the box to up stream applications.
Here’s a quick overview of our architecture:
LLM Service: Hosts the main language model (LLM) which generates responses based on refined prompts.
Agent Service: Hosts multiple agents, each responsible for a specific aspect of prompt refinement.
Deployment Workflow: Orchestrates the interaction between the LLM and the agents.
Before we start make sure you have the latest version of covalent-cloud which you can get by
pip install covalent-cloud -U
and make sure you sign up to Covalent Cloud
Step 1: Setting Up Your Environment
First, we need to set up two distinct environments in Covalent Cloud. One will host the main LLM, while the other will run our prompt-refining agents. This separation ensures that each component has the appropriate resources and dependencies. In the background, Covalent Cloud will create a distributed Docker environment that’s accessible via all the compute nodes. This setup allows us to avoid dealing with Docker files or complex configurations—everything is managed through Python, simplifying our workflow. Learn more about creating envs here.
Note that environment creation will take a few minutes, so please be patient! Alternatively, you can do this asynchronously by setting wait=False (default) in the create_env function. Make sure check the UI to confirm the environment is ready before proceeding.
import covalent_cloud as cc
# cc.save_api_key("YOUR-API-KEY")
cc.create_env(name="vllm", pip=["vllm==0.5.1", "torch==2.3.0"], wait=True)
Environment Already Exists.
Step 2: Define the Agent Classes
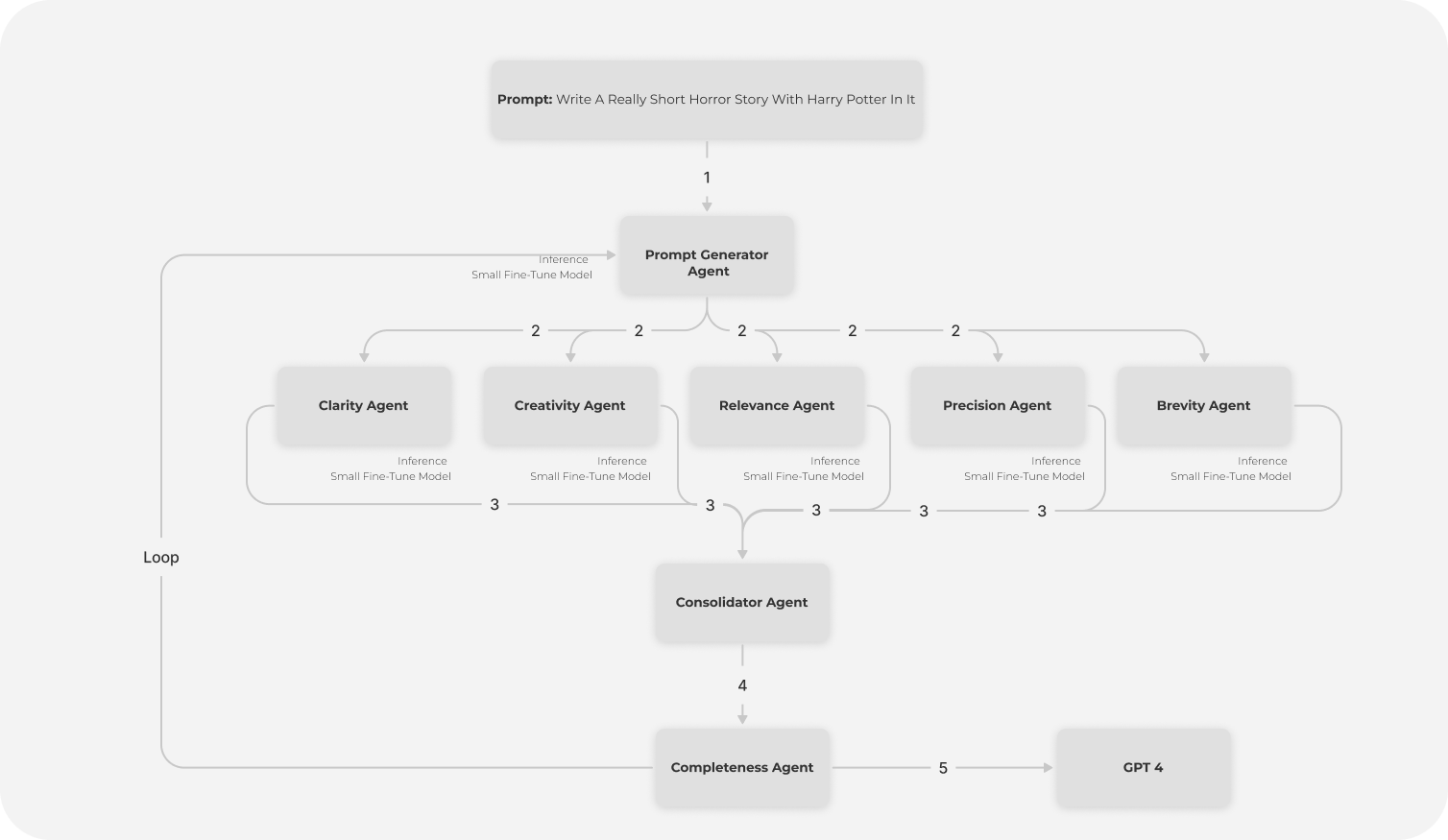
To refine the prompts, we'll create custom agent classes. Each agent will have a specific role, such as improving clarity, relevance, or creativity. These agents will collaborate to iteratively enhance the prompts. By using smaller models for these agents, we efficiently preprocess the prompts before they are passed to the larger LLM, saving valuable compute resources. In our case we will be choosing Llama-3 8B model
class Agent:
def __init__(self, name, role, function):
self.name = name
self.role = role
self.function = function
def query_llm(self, input_prompt):
"""Simulates querying the LLM with a role-specific prompt."""
system_prompt=f"You are a: {self.name}. Your role: {self.role}. Your function: {self.function}."
full_prompt=f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|>{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>Based on your role and function, give the modified new prompt for the following with a new prompt. Do not give me anything else other than the prompt:{input_prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>"""
return full_prompt
class CompletenessAgent(Agent):
def query_llm(self, input_prompt, original_task):
"""Ensures the final prompt includes all critical components from the original task."""
system_prompt=f"You are a: {self.name}. Your role: {self.role}. Your function: {self.function}."
full_prompt=f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
Original Task: {original_task}
# Final Prompt: {input_prompt}
# Make sure the final prompt contains all requirements of the original task. Modify the prompt if necessary and return only the final prompt.<|eot_id|><|start_header_id|>assistant<|end_header_id|>"""
return full_prompt
Next, we define the respective agents.
agents = [
Agent(
"Prompt Generator Agent",
"You are an agent that generates the initial prompt based on a broad description of the user's task.",
"Translates a user's vague or broad task description into a clear, actionable prompt that can be processed by other agents. you aims to create a prompt that is specific enough to start the refinement process but general enough to allow for creative input."
),
Agent(
"Clarity Agent",
"You are an agent that enhances the clarity and understandability of the prompt.",
"Reviews the prompt for clarity, checking for ambiguous language, confusing structure, and overly complex vocabulary. Simplify sentences and clarifies intentions."
),
Agent(
"Relevance Agent",
"You are an agent that ensures the prompt remains focused on the user's original intent and relevant to the task at hand.",
"Assesses whether the prompt directly addresses the core elements of the user's question or task. Remove extraneous details and sharpens the focus."
),
Agent(
"Precision Agent",
"You are an agent that increases the precision of the prompt, asking for specific details to narrow down the response scope.",
"Tighten the prompt to target very specific information or answers, facilitating more detailed and targeted responses."
),
Agent(
"Creativity Agent",
"You are an agent that encourages more imaginative and innovative responses from the LLM.",
"If you think the prompt can benefit from creativity Rewrite the prompt to invite creative thinking and more novel responses. you might pose the question in a hypothetical scenario or ask for a metaphorical explanation."
),
Agent(
"Contextualization Agent",
"You are an agent that adds necessary context to the prompt, setting the stage for responses that are informed by relevant background information.",
"Ensure that the prompt includes sufficient context to be fully understood and appropriately answered. This may involve adding historical, scientific, or cultural context."
),
Agent(
"Engagement Agent",
"You are an agent that makes the prompt more engaging and interactive to potentially increase the richness of the response.",
"Design the prompt to capture interest and provoke thoughtful, detailed responses. you might use rhetorical questions, direct challenges, or engagement tactics like asking for opinions or personal interpretations."
),
Agent(
"Brevity Agent",
"You are an agent that focuses on streamlining the prompt to make it as concise as possible while maintaining its effectiveness.",
"Trim down the prompt to its most essential elements, removing any redundant words or phrases and ensuring that every word serves a purpose."
),
Agent(
"Consolidator Agent",
"You are the consolidator agent responsible for synthesizing the best responses from other agents into a single optimized prompt.",
"Review suggestions from all other agents merge the elements from multiple suggestions into a single refined prompt. Give me back the final prompt and nothing else. Do not add anything like 'here is the final prompt' or 'this is the final prompt' etc.."
),
CompletenessAgent(
"Completeness Agent",
"You are responsible for ensuring that the final prompt is complete and faithful to the original task.",
"Review the final consolidated prompt and ensure it contains all necessary elements from the original task description. Adjust as needed to include any missing aspects, apart from making the prompt better the prompt should contain the same meaning as that of the original task. Give me back the final prompt and nothing else. Do not add anything like 'here is the final prompt' or 'this is the final prompt' etc.."
)
]
Step 3: Define the LLM Service
Next, we define a service to deploy the LLM using Covalent Cloud. This service will be responsible for generating responses based on the prompts refined by our agents. The LLM service will leverage GPUs which again can be tuned purely from python via the executor object. In this example we will be using one A100 GPU, and we will ensure that the service is only up for 10 days.
executor = cc.CloudExecutor(
env="vllm",
num_cpus=2,
num_gpus=1,
memory="25GB",
gpu_type=cc.cloud_executor.GPU_TYPE.A100,
time_limit="10 days",
)
@cc.service(executor=executor, name="small-llm")
def vllm_llama(model):
"""Initializes the LLM model for text generation."""
from vllm import LLM
llm_instance = LLM(model=model, trust_remote_code=True, enforce_eager=True)
return {"llm_instance": llm_instance}
@vllm_llama.endpoint("/generate")
def generate(llm_instance, full_prompt, num_tokens=1500):
"""Generates text based on the input prompt using the specified LLM model."""
from vllm import SamplingParams
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, max_tokens=num_tokens)
responses = llm_instance.generate(full_prompt, sampling_params)
texts = []
for response in responses:
generated_texts = response.outputs[0].text
texts.extend(generated_texts)
return texts
Step 4: Define the Agent Service
We will now define the agent service that will host our prompt-refining agents. This service will coordinate the agents to process and refine the prompts iteratively.
executor = cc.CloudExecutor(env="vllm", num_cpus=2, memory="24GB", time_limit="10 days")
@cc.service(executor=executor,name="Prompt Agent",auth=False)
def agent_service(llm_model,agents):
"""Service that refines prompts using a sequence of agents."""
def llm_brain(prompt_list,num_tokens=1500):
return "".join(llm_model.generate(full_prompt=prompt_list, num_tokens=num_tokens))
return {"agents":agents,"llm_brain":llm_brain}
@agent_service.endpoint("/improve_prompt")
def improve_prompt(agents,llm_brain,prompt,iterations):
"""Refine a prompt using multiple agents in sequence."""
current_prompt = llm_brain(agents[0].query_llm(prompt)) # PGA generates the initial prompt
previous_prompt = []
for _ in range(iterations):
# Refine the prompt with each evaluation agent
refined_prompts = llm_brain([agent.query_llm(current_prompt) for agent in agents[1:-2]]) # Skip PGA and CA
# Consolidate the refined prompts
combined=" | ".join([f"agent name: {i.name} agent role {i.role} prompt generated:{j}" for i,j in zip(agents[1:-2],refined_prompts)])
if previous_prompt:
for i,j in enumerate(previous_prompt):
combined = combined+f" previous iteration consolidated prompts iteration {i} : {j}"
combined = combined+" Original Prompt: " + prompt
consolidated_prompt = llm_brain(agents[-2].query_llm(combined))
current_prompt = llm_brain(agents[-1].query_llm(consolidated_prompt, prompt))
# Update the current prompt for the next iteration
current_prompt = consolidated_prompt
previous_prompt.append(current_prompt)
return current_prompt
Step 5: Deploy and Interact with the Services
Deploying our services in Covalent Cloud involves hosting them on Covalent's powerful compute backends. Once deployed, these services will stay active, allowing us to interact with them via custom APIs. We will define endpoints for our services, including streaming endpoints, to enable real-time interactions and monitor the progress of prompt refinements.
Note here that we now define a covalent workflow, which will iteratively deploy these services and pass the required information between them. This is a powerful feature of Covalent Cloud, allowing us to define complex workflows in a simple and intuitive manner.
Depending on the deployment hardware and model download bandwidth this can take a few minutes to complete.
import covalent as ct
wf_executor = cc.CloudExecutor(
env="vllm", num_cpus=10, memory="10GB", time_limit="2 hours"
) # simple cheap executor for running the workflow function
@ct.lattice(executor=wf_executor, workflow_executor=wf_executor)
def prompt_refinement_workflow(model, agents):
llama_api = vllm_llama(model=model)
agent_endpoint = agent_service(llama_api, agents)
return agent_endpoint
run_id = cc.dispatch(prompt_refinement_workflow)(
model="unsloth/llama-3-8b-Instruct", agents=agents
)
print(run_id)
a17841e2-265a-4b36-9bda-bfc99cf362b7
run=cc.get_result(run_id, wait=True)
run.result.load()
agent=run.result.value
print(agent)
╭───────────────────────── Deployment Information ─────────────────────────╮
│ Name Prompt Agent │
│ Description Service that refines prompts using a sequence of agents. │
│ Function ID 6643b0aaf7d37dbf2a46892c │
│ Address https://fn.prod.covalent.xyz/06643b0aaf7d37dbf2a46892c │
│ Status ACTIVE │
│ Tags │
│ Auth Enabled No │
╰──────────────────────────────────────────────────────────────────────────╯
╭───────────────────────────────────────────────────────────────────╮
│ POST /improve_prompt │
│ Streaming No │
│ Description Refine a prompt using multiple agents in sequence. │
╰───────────────────────────────────────────────────────────────────╯
From here one can use the endpoints directly via curl or any other http client to interact with the services. Or one can also use the returned deployment object in itself to directly interact with the service endpoint via functional calls. We will use the latter approach to interact with the services, see here to know more about how to interact with the services.
Usage and testing
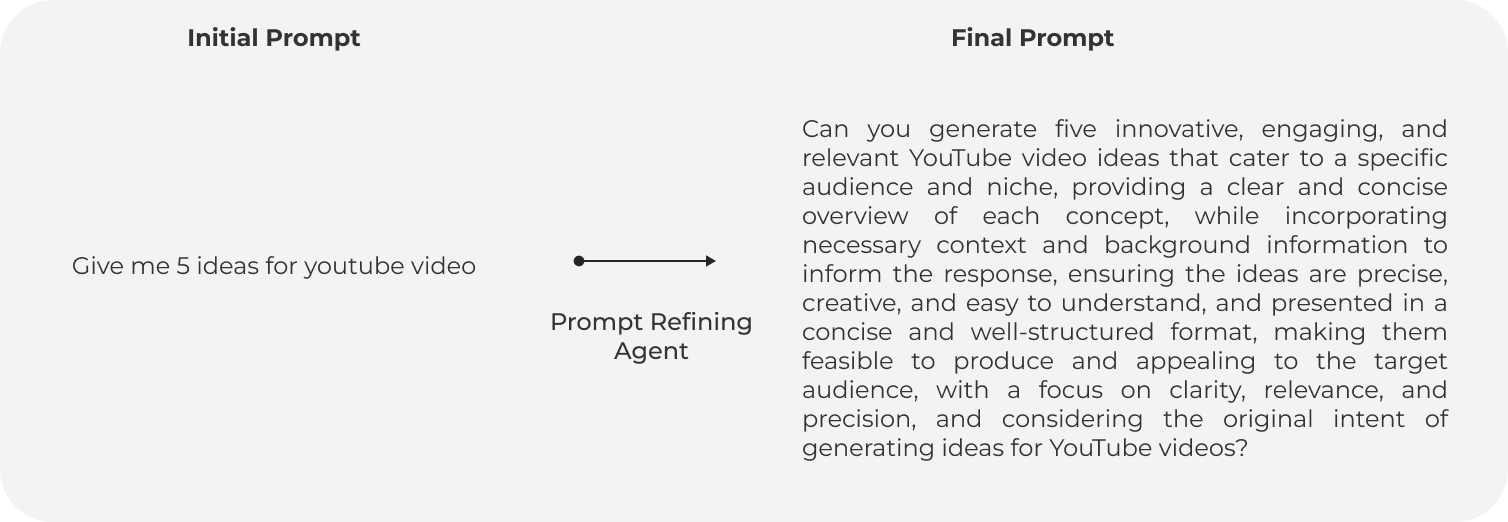
To validate the effectiveness of our multi-agent prompt refining application, we conducted a test using OpenAI's GPT-3.5 model. We provided an initial simple prompt and an improved, refined prompt generated by our multi-agent system. The goal was to compare the responses from GPT-3.5 to see how much the refinement process improves the quality and depth of the generated content. Here we will arbitrarily choose number of iterations to be 5, but this can be changed as per the requirement.
prompt="write a really short horror story with harry potter in it "
iterations=5
improved_prompt=agent.improve_prompt(prompt=prompt,iterations=iterations)
Let's test the prompts with the GPT-3.5 model, please make sure to add your OpenAI API key in the below cell to test the prompts.
open_ai_key="your-open-ai-key-here"
def ask_gpt(prompt):
from openai import OpenAI
client = OpenAI(api_key=open_ai_key)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "you are an helpful assistant that will answer anything I ask you."},
{"role": "user", "content": prompt}
]
)
return completion.choices[0].message.content
improved_prompt_gpt=ask_gpt(improved_prompt)
original_prompt_gpt=ask_gpt(prompt)
Let's write a quick function to format the texts.
from IPython.display import display, HTML
import html
def display_comparison_table(original_prompt, improved_prompt, original_prompt_gpt, improved_prompt_gpt):
table_html = f"""
Prompt Comparison
Initial PromptFinal Prompt
Prompts{html.escape(original_prompt)}{html.escape(improved_prompt)}
GPT 3.5 Response{html.escape(original_prompt_gpt)}{html.escape(improved_prompt_gpt)}
"""
display(HTML(table_html))
display_comparison_table(prompt, improved_prompt, original_prompt_gpt, improved_prompt_gpt)
Prompt Comparison
| Initial Prompt | Final Prompt | |
|---|---|---|
| Prompts | write a really short horror story with harry potter in it | Here is the modified prompt: "Craft a hauntingly concise and immersive horror story within the Harry Potter universe, focusing on the darker aspects of the wizarding world and highlighting Harry's bravery and determination as he confronts the terror that lurks beneath the surface, incorporating specific details to make the narrative chilling and engaging, while maintaining a concise and relevant narrative that remains true to the original intent of the task, with a focus on precision and clarity to ensure a coherent and terrifying tale that explores the wizarding world's darker corners, and sparks the reader's imagination with creative and contextualized elements that bring the story to life." |
| GPT 3.5 Response | In the dark corridors of Hogwarts, Harry Potter heard a soft whisper calling his name. Ignoring the warning signs, he followed the eerie voice deeper into the forbidden chambers of the castle. Suddenly, the walls started closing in on him, trapping him in a nightmarish maze of shifting shadows. As fear gripped his heart, a hooded figure emerged from the darkness, its eyes glowing with malice. Harry realized too late that he had wandered into the domain of a dark wizard who sought to claim his soul. The last thing he saw before the world faded to black was the twisted smile of Lord Voldemort, as he whispered, "Avada Kedavra." | In the depths of the Forbidden Forest, a sinister force stirred, casting a shadow over Hogwarts School of Witchcraft and Wizardry. Reports of students' mysterious disappearances spread like wildfire, shrouded in fear and uncertainty. Whispers of a malevolent presence crept through the castle walls, chilling even the bravest of hearts. Harry Potter, ever vigilant and determined, sensed the looming danger and took it upon himself to investigate. Armed with his wand and unwavering courage, he navigated the dimly lit corridors and hidden passages, following the trail of darkness that seemed to grow stronger with each step. As he delved deeper into the secrets of the forest, Harry encountered spectral figures and unearthly apparitions, each one a testament to the horrors that dwelled within. The oppressive atmosphere weighed heavily on him, but he pressed on, his Gryffindor spirit driving him forward in the face of terror. At the heart of the forest, Harry confronted the source of the malevolence – a powerful dark wizard who had long been thought vanquished. Their duel was a clash of magic and will, each spell casting eerie shadows that danced in the darkness. In a final act of bravery, Harry tapped into a reservoir of strength he never knew he had, channeling the courage of his friends and the love that bound them together. With a blinding burst of light, he banished the dark wizard back into the depths from which he came, restoring peace to the forest and Hogwarts once more. As the sun rose over the horizon, casting its warm rays over the castle grounds, Harry Potter emerged from the forest, weary but triumphant. The echoes of the night's terrors faded into whispers, a harrowing tale that would be whispered for generations to come – a testament to the courage and resilience of the Boy Who Lived. |
We clearly see that with a refined prompt, we get a much richer and more detailed response from GPT-3.5 compared to using the original simple prompt. Note that this is just an example, but one can think of fine-tuning these specialized agents for further honing the skills or making more domain-specific prompts better. For instance, for story use cases, we might want more specialized agents like creativity, fantasy, etc. For science, we can have field-dependent specialized agents working to improve the prompt, such as in fields like chemistry, physics, or biology.
Note
Once done, make sure to teardown the services either from UI or from SDK.
Conclusion
This test demonstrates the significant improvement in the quality of responses generated by GPT-3.5 when using refined prompts created by our multi-agent system. By leveraging smaller models to refine prompts before sending them to larger, more computationally expensive models, we can optimize resource usage and achieve better results.
The multi-agent approach not only enhances the clarity and relevance of the prompts but also adds depth and creativity, resulting in responses that are more engaging and informative. This methodology can be adapted and extended to various domains, making it a powerful tool for enhancing the performance and efficiency of AI applications.
By using Covalent Cloud, we simplify the deployment and management of these complex workflows, ensuring that our focus remains on developing innovative solutions rather than dealing with infrastructure challenges. The ability to easily create, deploy, and scale multi-agent systems opens up new possibilities for AI-driven applications, making Covalent Cloud an invaluable asset in the AI developer's toolkit.