Serving a Llama-Based Chatbot Model
Chatbots are arguably the genesis of the current AI Boom. Chatbots have been around in one form or another for some time now, but since the advent of Large Language Models (LLMs) like GPT, they've become much more sophisticated and capable!
In this tutorial, we'll learn to serve our own LLM Chatbot using Covalent Cloud and Hugging Face Transformers.
Frontend
We've also created a Streamlit GUI for this chatbot! See the Covalent Showcase repository for how to set this up.
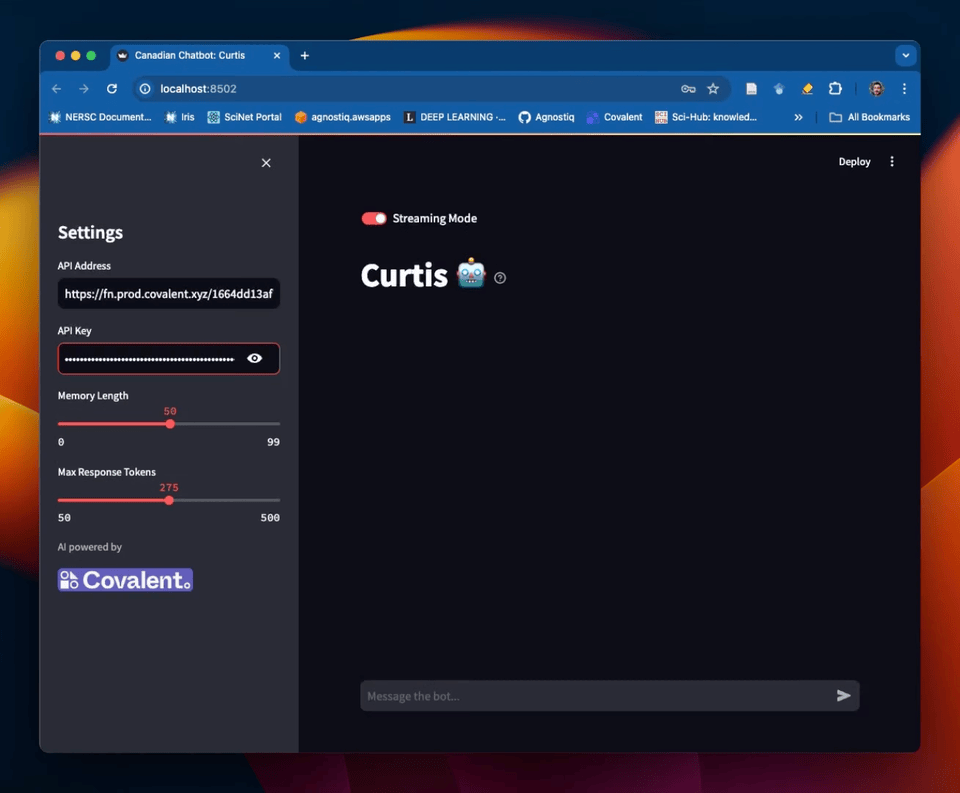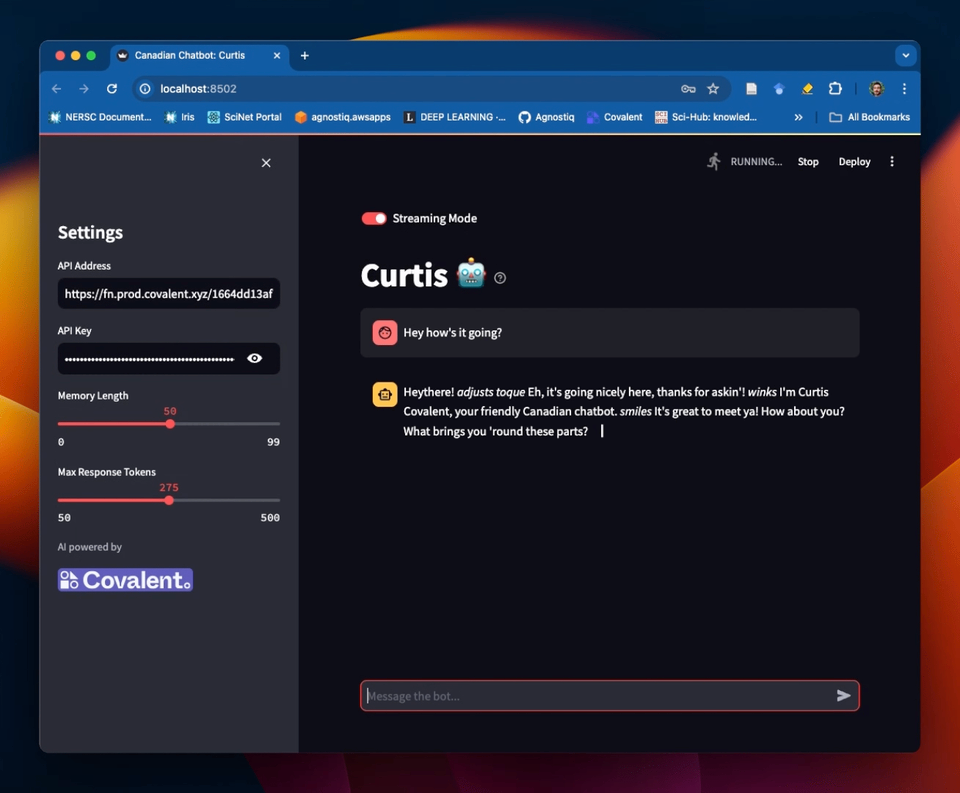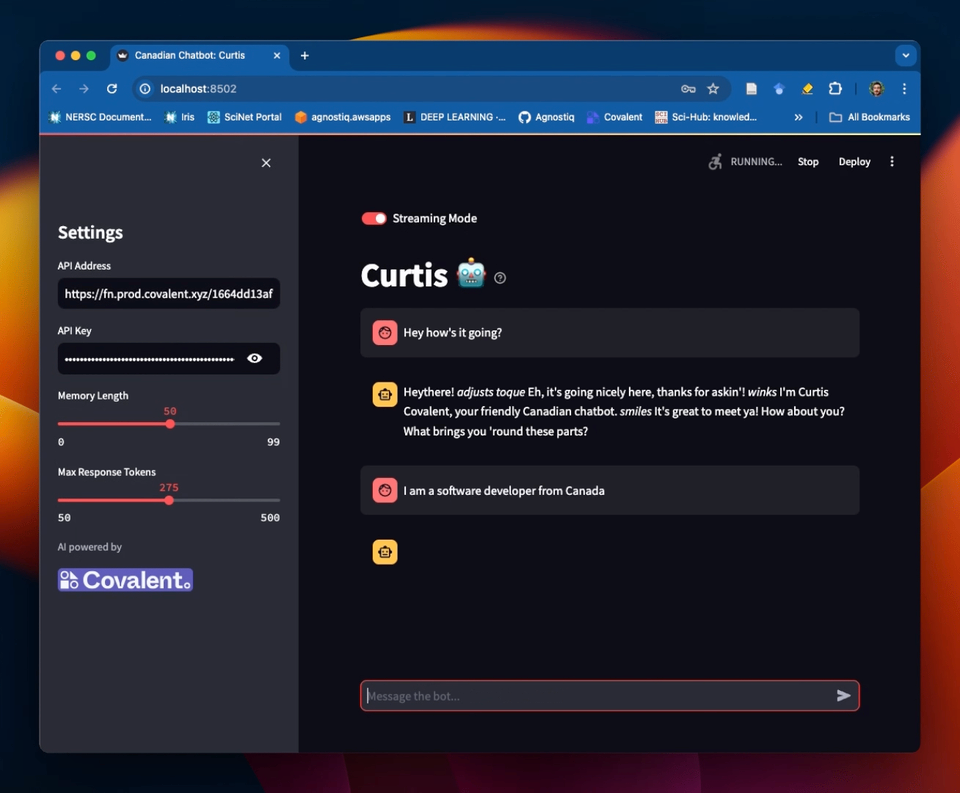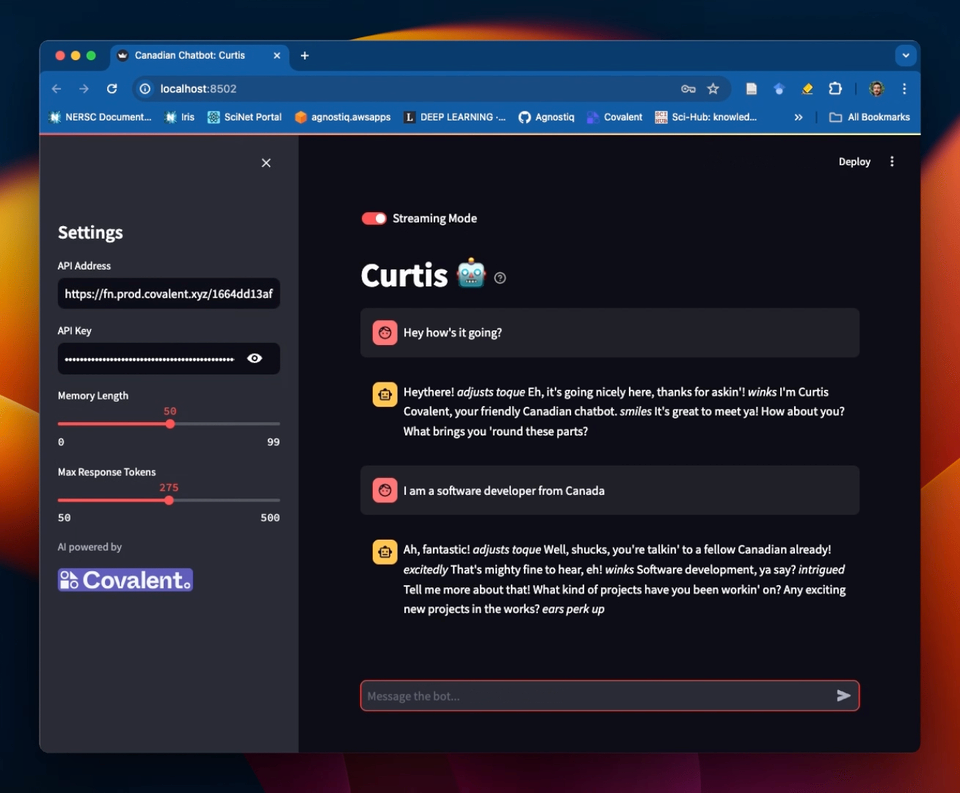
Example of a Streamlit frontend for the chatbot service in this tutorial
Local Environment
Before you start, make sure you've installed the Covalent Cloud SDK.
pip install -U covalent-cloud
Once that's done, import covalent_cloud. We'll avoid requiring any other local dependencies going forward.
import covalent_cloud as cc
Next, save your Covalent Cloud API key if you haven't done so already.
# cc.save_api_key("you-api-key")
Cloud Environment
The service in this tutorial will use the environment below.
Environment creation can take a few minutes... Fortunately, we only need to do it once! The environment can be referenced by name (i.e. "chatbot-tutorial") thereafter.
Remember, these are remote dependencies -- we don't necessarily need them to be installed locally.
cc.create_env(
name="chatbot-tutorial",
pip = ["accelerate", "sentencepiece", "transformers"],
wait=True
)
Define a Set of Compute Resources
Executors specify a set of modular compute resources.
This particular executor specifies 4 CPUs, 54 GB of RAM, and a single NVIDIA L40 GPU. We'll assign it to our service in the next step.
gpu_executor = cc.CloudExecutor(
env="chatbot-tutorial",
num_cpus=4,
memory="54 GB",
gpu_type="l40",
num_gpus=1,
time_limit="3 hours",
)
Serving The Chatbot Model
Every function service in Covalent Cloud contains an initializer function and any number of API endpoints.
We'll start with an initializer that creates a text generation pipeline.
@cc.service(executor=gpu_executor, name="LLM Chatbot Server")
def chatbot_backend(model_path, device_map="auto"):
"""Create a Llama2 chatbot server."""
# Importing here avoids local dependencies.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from torch import float16
model = AutoModelForCausalLM.from_pretrained(
model_path, device_map=device_map, torch_dtype=float16, do_sample=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
return {"pipe": pipe}
Next, let's add a simple endpoint that generates a response from the chatbot.
@chatbot_backend.endpoint("/generate-response", name="Generate Response")
def generate(pipe, prompt, max_new_tokens=50):
"""Generate a response to a prompt."""
output = pipe(
prompt, max_new_tokens=max_new_tokens,
do_sample=True, truncation=True, temperature=0.9
)
gen_text = output[0]['generated_text']
return gen_text
We'll also add an alternative endpoint that streams the response back to the client, as it's being generated. See here for more on streaming endpoints.
The key difference is that we specify stream=True in the endpoint decorator, and we yield responses instead of return-ing just one.
@chatbot_backend.endpoint("/stream-response", name="Stream Response", streaming=True)
def generate_stream(pipe, prompt, max_new_tokens=200):
"""Generate a response to a prompt, streaming tokens."""
# Avoid local torch dependency.
# Import `torch` as usual, at the top of this notebook, to avoid this.
from torch import ones
def _starts_with_space(tokenizer, token_id):
token = tokenizer.convert_ids_to_tokens(token_id)
return token.startswith('▁')
model = pipe.model
tokenizer = pipe.tokenizer
_input = tokenizer(prompt, return_tensors='pt').to("cuda")
for output_length in range(max_new_tokens):
# Generate next token
output = model.generate(
**_input, max_new_tokens=1, do_sample=True,
temperature=0.9, pad_token_id=tokenizer.eos_token_id
)
# Check for stopping condition
current_token_id = output[0][-1]
if current_token_id == tokenizer.eos_token_id:
break
# Decode token
current_token = tokenizer.decode(
current_token_id, skip_special_tokens=True
)
if _starts_with_space(tokenizer, current_token_id.item()) and output_length > 1:
current_token = ' ' + current_token
yield current_token
# Update input for next iteration.
# Output grows in size with each iteration.
_input = {
'input_ids': output.to("cuda"),
'attention_mask': ones(1, len(output[0])).to("cuda"),
}
Deploy The Service
The first line below will asynchronously deploy the service. In the lines that follow, we wait for the service to be active, then print some information about it.
Once the cell below is executed, you'll have a running chatbot service! Deployment usually takes less than 15 minutes.
chatbot = cc.deploy(chatbot_backend)(model_path="NousResearch/Llama-2-7b-chat-hf")
# Wait for active state and reload the client.
chatbot = cc.get_deployment(chatbot.function_id, wait=True)
# Print information about the deployment.
print(chatbot)
╭──────────────────────── Deployment Information ────────────────────────╮
│ Name LLM Chatbot Server │
│ Description Create a Llama2 chatbot server. │
│ Function ID 6650d66ef7d37dbf2a468ba6 │
│ Address https://fn.prod.covalent.xyz/16650d66ef7d37dbf2a468ba6 │
│ Status ACTIVE │
│ Tags │
│ Auth Enabled Yes │
╰────────────────────────────────────────────────────────────────────────╯
╭─────────────────────────────────────────────────╮
│ POST /generate-response │
│ Streaming No │
│ Description Generate a response to a prompt. │
╰─────────────────────────────────────────────────╯
╭───────────────────────────────────────────────────────────────────╮
│ POST /stream-response │
│ Streaming Yes │
│ Description Generate a response to a prompt, streaming tokens. │
╰───────────────────────────────────────────────────────────────────╯
Authorization token: JetGczt2r3ObgAtcXcjWHfwMIEjcnPUqkpUJQ3kY5-sYChzSakW89ddEiCq7b5CnNiRwQbFOVa6LWmAmS-w1mw
Chatting with The Bot
Basic Response Generation
Now that the service is active, let's chat with the bot by sending requests to the "/generate-response" endpoint. Note that all endpoints are attached to our Python client automatically.
A raw prompt like the one below will generate a mediocre response. (We can do better!)
chatbot.generate_response(prompt="What is the meaning of life?")
'What is the meaning of life? Why are we here? What is the purpose of our existence?
The questions about the meaning of life have been debated and discussed for centuries,
and there are many different perspectives and philosophies on the topic. Some beliefs hold that'
Improved Response Generation
To get better responses, we should utilize the prompt format specified for the model. For example:
PROMPT_TEMPLATE = """<s>[INST] <<SYS>>
You are a friendly chatbot with deep philosophical knowledge.
Consider the user's prompt and generate a thoughtful response.
<</SYS>>
[/INST] {prompt}"""
prompt = PROMPT_TEMPLATE.format(prompt="What is the meaning of life?")
response = chatbot.generate_response(prompt=prompt)
# Remove the leading instructions and prompt.
print(response.replace(prompt, "").strip())
This is a question that has puzzled philosophers and thinkers throughout history, and there are many different perspectives on the matter. As a chatbot with a deep understanding of philosophy, I can offer some insights on this question.
Let's try again for a longer response with the same prompt. We can do this by specifying a max_new_tokens value to override the default (50) in the endpoint definition.
response = chatbot.generate_response(prompt=prompt, max_new_tokens=500)
# Remove the leading instructions and prompt.
print(response.replace(prompt, "").strip())
Is it to be happy, find purpose, or something else entirely? As a friendly chatbot with deep philosophical knowledge, I must say that the answer to this question is complex and multifaceted.
One way to approach the question is to consider the nature of existence itself. According to some philosophical perspectives, life is merely a brief moment in the vast expanse of time and space,
and our existence is inherently meaningless in the grand scheme of things.
However, this perspective fails to take into account the profound impact that individuals and communities can have on the world around them.
From a more optimistic viewpoint, life's meaning can be found in the relationships we form with others, the experiences we have, and the positive impact we can have on the world.
In this sense, life is not just about surviving and reproducing, but also about creating meaning and purpose through our actions and choices.
Another way to approach the question is to consider the role of consciousness and self-awareness in our understanding of life's meaning.
Some philosophers argue that consciousness is the fundamental aspect of existence, and that our ability to reflect on and understand the world is what gives life its meaning.
Ultimately, the meaning of life is a deeply personal and subjective question, and there is no one right answer. Different people may find meaning in different things,
whether it be their relationships, their work, their impact on the world, or simply their own personal experiences and perspectives.
As a friendly chatbot, I must say that I find meaning in helping others and providing thoughtful and informative responses to their questions.
I hope that my answers have been helpful in providing a deeper understanding of this complex and multifaceted question.
Streaming Responses
Finally, let's try streaming a response from the chatbot.
prompt = PROMPT_TEMPLATE.format(prompt="Does everyone see colors the same way?")
for k in chatbot.stream_response(prompt=prompt, max_new_tokens=500):
print(k.decode(), end="")
# You should see the output update in real-time when you run this cell.
Interesting question! The short answer is no, not everyone sees colors the same way. In fact, the way we perceive colors is a complex process that involves several factors,
including the structure and function of our eyes, the lighting conditions, and even our cultural background and individual experiences.
Firstly, it's important to understand that colors are not an objective quality of the physical world, but rather a subjective experience that our brains interpret from the light that enters our eyes.
Different animals may have different visual systems and may therefore perceive colors differently.
For example, some animals, like dogs, have only two types of cones in their retinas, which means they can only see in shades of blue and yellow, but not in red.
Humans, on the other hand, have trichromatic vision, meaning we have three types of cones that are sensitive to different wavelengths of light.
This allows us to perceive a wide range of colors, including red, green, and blue.
However, even among humans, there can be variations in color perception due to differences in the structure and sensitivity of our eyes.
For example, some people may have conditions that affect their color vision, such as color blindness or sensitivity to certain wavelengths of light.
Additionally, cultural background and individual experiences can also influence how we perceive colors.
For example, in some cultures, red is associated with good luck and prosperity, while in others it's associated with violence and anger.
Similarly, some people may have personal experiences or associations that affect how they perceive colors.
In conclusion, color perception is a complex and multi-faceted process that involves both objective physical factors and subjective individual experiences.
While we may perceive colors in a similar way, there can be variations and differences in how they are perceived across different people and cultures.
Danger Zone!
Run the cell below to tear down the deployment and release all its resources. (You can also do this from the Covalent Cloud UI.)
# import covalent_cloud as cc
# chatbot = cc.get_deployment("6650d66ef7d37dbf2a468ba6")
chatbot.teardown()
'Teardown initiated asynchronously.'