Building a Scalable Re-Ranking RAG Pipeline with Covalent, NVIDIA NIMs, and Snowflake
In this tutorial, we'll dive deep into creating a sophisticated Retrieval-Augmented Generation (RAG) pipeline. We'll leverage the power of Covalent, an open-source workflow orchestration platform, to seamlessly integrate multiple NVIDIA NeMo Inference Microservices (NIMs) and Snowflake for data storage. This combination of technologies allows us to build a robust, scalable, and efficient AI system capable of handling complex language tasks. Our RAG pipeline will consist of three key components:
- Llama3 8B Instruct Model: A powerful language model based on Meta's Llama architecture, fine-tuned for instruction following. This model will generate our final responses.
- Arctic Embed L: An embedding model that converts text into high-dimensional vector representations, allowing for efficient semantic search.
- NV RerankQA Mistral 4B: A specialized model for re-ranking retrieved passages, ensuring the most relevant context is used for generation.
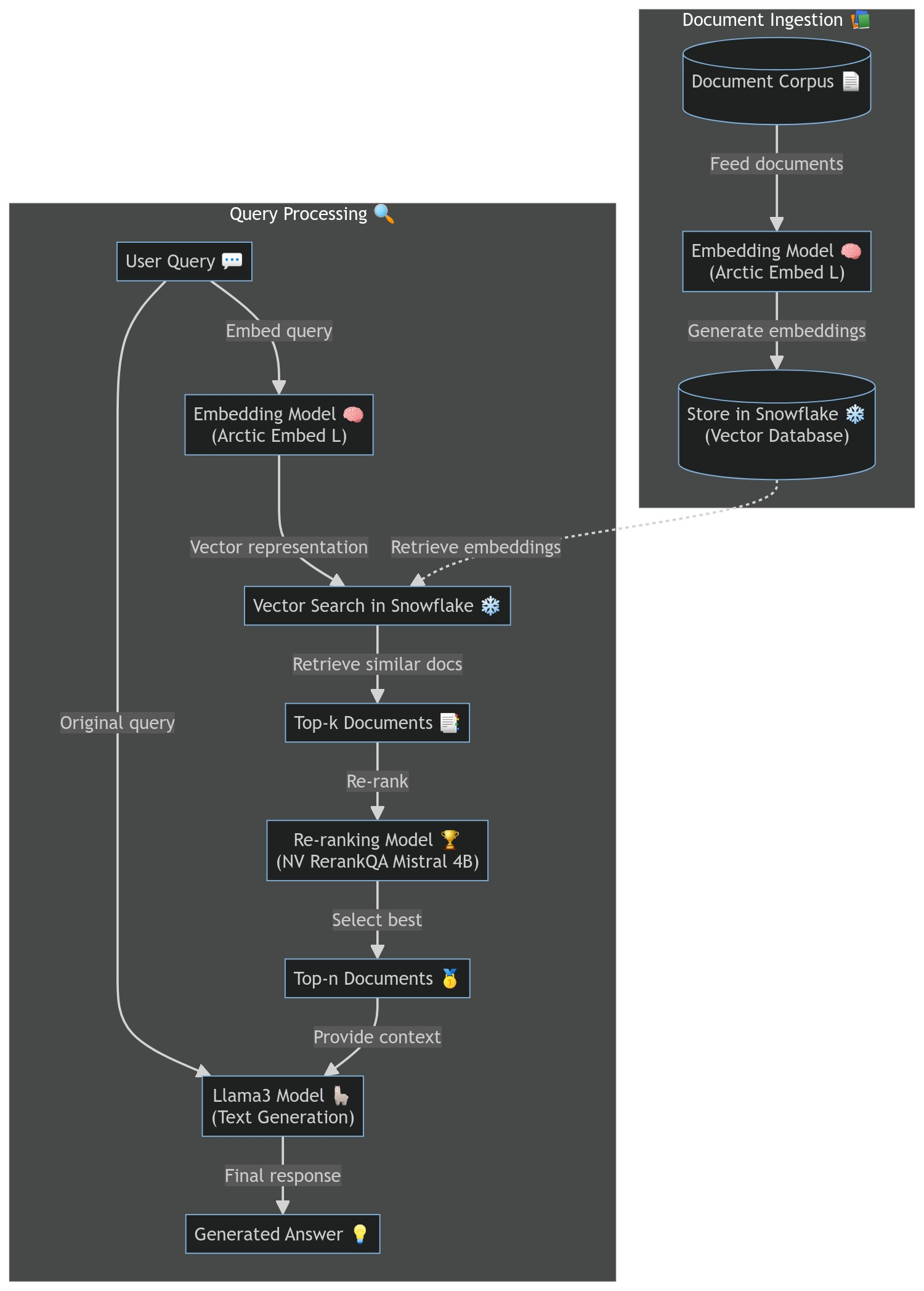
This diagram illustrates the flow of our RAG pipeline:
The user's query is embedded using the Arctic Embed L model. We perform a vector search in Snowflake to find similar documents. The top-k documents are retrieved and passed to the re-ranking model. The NV RerankQA Mistral 4B model re-ranks the documents, and we select the top-n. These documents, along with the original query, are sent to the Llama3 8B Instruct model. The Llama3 model generates the final response.
In parallel, we have a process for ingesting new documents:
Documents are embedded using the Arctic Embed L model. These embeddings are stored in Snowflake for future retrieval.
import os
import time
import warnings
import covalent_cloud as cc
import requests
First, we'll save our Covalent Cloud API key and our Nvdia NGC API Key for enterprise.
cc.save_api_key("<YOUR_API_KEY>") # Save Covalent Cloud API key
cc.store_secret("NGC_API_KEY", "<YOUR_API_KEY>") # Set the nvidia NGC Enterprise API key as a secret
These environments are crucial for running our NIM services. Each environment is based on a specific NVIDIA container image, ensuring compatibility and optimal performance. The Snowflake environment includes the necessary Python connector for interacting with our Snowflake database. (Note that these environments are being wait(ed) for, so the code execution will pause until they are ready to use.)
cc.create_env(
name="nim-llama3-8b-instruct",
base_image="nvcr.io/nim/meta/llama3-8b-instruct:1.0.0",
wait=True
)
cc.create_env(
name="nim-arctic-embed-l",
base_image="nvcr.io/nim/snowflake/arctic-embed-l:1.0.1",
wait=True
)
cc.create_env(
name="nim-nv-rerankqa-mistral-4b-v3",
base_image="nvcr.io/nim/nvidia/nv-rerankqa-mistral-4b-v3:1.0.1",
wait=True
)
cc.create_env(
name="snowflake",
pip=["snowflake-connector-python"],
wait=True,
)
Environment Already Exists.
Environment Already Exists.
Environment Already Exists.
Environment Already Exists.
Some utilities for NIMs
We'll define some utility functions to help start and poll the NIM servers. These functions will simplify the process of managing the NIM services and ensure they are running before we proceed with the pipeline.
def start_nims_server(pythonpath):
os.system(
'unset VLLM_ATTENTION_BACKEND '
'&& '
f'PYTHONPATH={pythonpath} '
'/bin/bash '
'/opt/nvidia/nvidia_entrypoint.sh '
'/opt/nim/start-server.sh '
'&'
)
def poll_nims_server(url, headers, test_payload, max_wait_mins, poll_freq_secs):
secs = 0
timeout = max_wait_mins * 60
while True:
try:
response = requests.post(url, headers=headers, json=test_payload, timeout=timeout)
response.raise_for_status()
break
except:
time.sleep(poll_freq_secs)
secs += poll_freq_secs
if secs >= timeout:
warnings.warn(f"Server has not started after {secs} seconds!")
break
Now, let's implement our three NIM services:
Llama3 NIM
This service sets up and manages the Llama3 8B Instruct model. The /generate endpoint allows us to send prompts or message sequences to the model and receive generated responses.
llama3_exec = cc.CloudExecutor(
env="nim-llama3-8b-instruct",
memory="48GB",
num_gpus=1,
gpu_type="l40",
num_cpus=4,
time_limit="24 hours",
)
@cc.service(executor=llama3_exec, name="NIM Llama3 8B Service")
def nim_llama3_8b_service(max_wait_mins=15, poll_freq_secs=4):
# Start local server.
pythonpath = ":".join([
"/var/lib/covalent/lib",
"/usr/local/lib/python3.10/dist-packages",
])
start_nims_server(pythonpath)
# Poll server.
url = "http://localhost:8000/v1/chat/completions"
headers = {
"accept": "application/json",
"Content-Type": "application/json",
}
test_payload = {
"model": "meta/llama3-8b-instruct",
"messages": [{"role": "user", "content": "Hello, world!"}],
}
poll_nims_server(url, headers, test_payload, max_wait_mins, poll_freq_secs)
return {"url": url, "headers": headers}
@nim_llama3_8b_service.endpoint("/generate")
def generate(url=None, headers=None, *, prompt=None, messages=None, **kwargs):
"""Returns raw response JSON"""
if not (prompt or messages):
return "Please provide a prompt or a list of messages."
# Construct request.
payload = {"model": "meta/llama3-8b-instruct"}
# Handle message or prompt.
if messages:
payload["messages"] = messages
elif prompt:
payload["messages"] = [{"role": "user", "content": prompt}]
# Include any additional kwargs.
for k, v in kwargs.items():
payload[k] = v
# Forward request to local NIM server.
response = requests.post(
url=url, headers=headers, json=payload, timeout=300
)
response.raise_for_status()
return response.json()
Embedding NIM
The Arctic Embed L service provides text embedding capabilities. The /get_embedding endpoint allows us to convert text inputs into high-dimensional vector representations.
emb_exec = cc.CloudExecutor(
env="nim-arctic-embed-l",
memory="48GB",
num_gpus=1,
gpu_type="l40",
num_cpus=4,
time_limit="24 hours",
)
@cc.service(executor=emb_exec, name="NIM Arctic Embedding Service")
def nim_arctic_embed_service(max_wait_mins=15, poll_freq_secs=4):
# Start local server.
pythonpath = ":".join([
"/var/lib/covalent/lib",
"/usr/local/lib/python3.10/dist-packages",
"/usr/lib/python3.10/dist-packages",
"/app/src",
])
start_nims_server(pythonpath)
# Poll server.
url = "http://localhost:8000/v1/embeddings"
headers = {
"accept": "application/json",
"Content-Type": "application/json",
}
test_payload = {
"model": "snowflake/arctic-embed-l",
"input": ["Hello, world!"],
"input_type": "query",
}
poll_nims_server(url, headers, test_payload, max_wait_mins, poll_freq_secs)
return {"url": url, "headers": headers}
@nim_arctic_embed_service.endpoint("/get_embedding")
def get_embedding(url=None, headers=None, *, input=None, truncate="NONE"):
"""Returns raw response JSON"""
if not input:
return "Please provide an input text or list thereof."
# Construct request.
payload = {
"model": "snowflake/arctic-embed-l",
"input": input,
"input_type": "query",
"truncate": truncate,
}
# Forward request to local NIM server.
response = requests.post(
url=url, headers=headers, json=payload, timeout=300
)
response.raise_for_status()
return response.json()
Re-ranking NIM
The NV RerankQA Mistral 4B service helps in re-ranking retrieved passages. The /ranking endpoint takes a query and a list of passages, returning them in order of relevance.
rr_exec = cc.CloudExecutor(
env="nim-nv-rerankqa-mistral-4b-v3",
memory="48GB",
num_gpus=1,
gpu_type="l40",
num_cpus=4,
time_limit="24 hours",
)
@cc.service(executor=rr_exec, name="NIM RerankQA Service")
def nim_rerankqa_service(max_wait_mins=10, poll_freq_secs=4):
# Start local server.
pythonpath = ":".join([
"/var/lib/covalent/lib",
"/usr/local/lib/python3.10/dist-packages",
"/usr/lib/python3.10/dist-packages",
"/app/src",
])
start_nims_server(pythonpath)
url = "http://localhost:8000/v1/ranking"
headers = {
"accept": "application/json",
"Content-Type": "application/json",
}
test_payload = {
"query": {"text": "which way should i go?"},
"passages": [
{"text": "going left has only a 32 percent success rate on Tuesdays"},
{"text": "every Wednesday, going right is an extra 26% more likely to succeed"},
{"text": "it's a long way to the top if you wanna rock and roll"},
{"text": "any way you want it, that's the way you need it"},
]
}
poll_nims_server(url, headers, test_payload, max_wait_mins, poll_freq_secs)
return {"url": url, "headers": headers}
@nim_rerankqa_service.endpoint("/ranking")
def ranking(url=None, headers=None, *, query=None, passages=None):
"""Returns raw response JSON"""
if not (query and passages):
return "Missing query or passages"
# Construct request.
payload = {
"model": "nvidia/nv-rerankqa-mistral-4b-v3",
"query": query,
"passages": passages,
}
# Forward request to local NIM server.
response = requests.post(
url=url, headers=headers, json=payload, timeout=300
)
response.raise_for_status()
return response.json()
Inference Service
Next, we'll set up our Snowflake integration and create the RAG interface. This interface service ties everything together. It sets up the Snowflake connection, provides an endpoint for data ingestion, and implements the core RAG query logic. The /query_llama endpoint orchestrates the entire RAG process, from embedding the query to generating the final response.
WAREHOUSE_NAME = "nims_rag_warehouse"
DATABASE_NAME = "nims_rag_database"
SCHEMA_NAME = "nims_rag_schema"
TABLE_NAME = "nims_rag_table"
micro_ex = cc.CloudExecutor(
env="snowflake",
num_cpus=4,
memory="12GB",
time_limit="24 hours",
)
@cc.service(executor=micro_ex, name="NIM RAG Interface")
def interface_service(llama_client, emb_client, rr_client):
import snowflake.connector
conn = snowflake.connector.connect( # trial account
user="USERNAME",
password="PASSWORD",
account="HIDPBOM-AQ97412",
)
# Set up the Snowflake DB.
cursor = conn.cursor()
cursor.execute(f"CREATE WAREHOUSE IF NOT EXISTS {WAREHOUSE_NAME}")
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {DATABASE_NAME}")
cursor.execute(f"USE DATABASE {DATABASE_NAME}")
cursor.execute(f"CREATE SCHEMA IF NOT EXISTS {SCHEMA_NAME}")
cursor.execute(f"USE SCHEMA {DATABASE_NAME}.{SCHEMA_NAME}")
# Create the table if it does not exist.
cursor.execute(
f"CREATE OR REPLACE TABLE {TABLE_NAME} "
f"(text STRING, embedding VECTOR(float, 1024))"
)
return {
"conn": conn,
"llama_client": llama_client,
"emb_client": emb_client,
"rr_client": rr_client
}
@interface_service.endpoint("/ingest_data")
def ingest_data(conn, emb_client, *, data):
if not isinstance(data, list):
data = [data]
# Obtain embeddings from the Arctic Embedding service.
outputs = emb_client.get_embedding(input=data)
embeddings = [output["embedding"] for output in outputs['data']]
# Insert data and embeddings into the Snowflake DB.
cursor = conn.cursor()
for text, embedding in zip(data, embeddings):
cursor.execute(
f"INSERT INTO {TABLE_NAME}(text, embedding) "
f"SELECT '{text}', {embedding}::VECTOR(FLOAT, 1024)"
)
@interface_service.endpoint("/query_llama")
def query_llama(
conn, emb_client, rr_client, llama_client,
*,
prompt, retrieve=True, rerank=True, k=4, n=2
):
#--# Basic LLM #--#
if not retrieve:
# Generate a response using the Llama3 model.
response = llama_client.generate(prompt=prompt)
return response["choices"][0]["message"]["content"]
#--# Complete RAG #--#
# Obtain the query embedding.
query_embedding = emb_client.get_embedding(
input=[prompt])['data'][0]['embedding']
# Retrieve the top k texts from the Snowflake DB.
cursor = conn.cursor()
cursor.execute(
"SELECT text, "
f"VECTOR_COSINE_SIMILARITY(embedding, {query_embedding}::VECTOR(FLOAT, 1024)) "
"AS similarity FROM nims_rag_table "
"ORDER BY similarity DESC "
f"LIMIT {k}"
)
outputs = [t[0] for t in cursor.fetchall()]
retrieved = [output.strip('"') for output in outputs]
if rerank:
# Re-rank and get the the top n <= k texts.
outputs = rr_client.ranking(query={"text": prompt}, passages=[{"text": r} for r in retrieved])
ranked = [retrieved[o["index"]] for o in outputs["rankings"][:n]]
retrieved = ranked
messages = [
{"role": "system",
"content": "You are a helpful assistant. Note the following contextual data"},
{"role": "user",
"content": f"Consider this data when responding to my query: {retrieved}"},
{"role": "user",
"content": prompt}
]
response = llama_client.generate(messages=messages)
return response["choices"][0]["message"]["content"]
Deployment
Now that we have all our components, we'll deploy the RAG pipeline using Covalent's workflow capabilities. This workflow ties all our services together into a cohesive pipeline. Covalent's @lattice decorator allows us to define complex workflows easily, managing the dependencies and execution of our various services.
import covalent as ct
@ct.lattice(executor=micro_ex, workflow_executor=micro_ex)
def nims_rag_setup_workflow():
llama_client = nim_llama3_8b_service()
emb_client = nim_arctic_embed_service()
rr_client = nim_rerankqa_service()
return interface_service(llama_client, emb_client, rr_client)
dispatch_id = cc.dispatch(nims_rag_setup_workflow)()
print(dispatch_id)
a1292e4c-e25b-4db5-bf7f-c3e14749524a
res = cc.get_result(dispatch_id, wait=True)
res.result.load()
rag_client = res.result.value
print(rag_client)
╭──────────────────────────────── Deployment Information ────────────────────────────────╮
│ Name NIM RAG Interface │
│ Description Add a docstring to your service function to populate this section. │
│ Function ID 66b5fe11a158acd30e0d4c3f │
│ Address https://fn-a.prod.covalent.xyz/66b5fe11a158acd30e0d4c3f │
│ Status ACTIVE │
│ Auth Enabled Yes │
╰────────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────── Endpoints ───────────────────────────────────────╮
│ Route POST /ingest_data │
│ Streaming No │
│ Description Either add a docstring to your endpoint function or use the endpoint's │
│ 'description' parameter to populate this section. │
│ │
│ Route POST /query_llama │
│ Streaming No │
│ Description Either add a docstring to your endpoint function or use the endpoint's │
│ 'description' parameter to populate this section. │
╰────────────────────────────────────────────────────────────────────────────────────────╯
Authorization token:
hp8E_I0glebweXv_HTGXYJuptOCbHyJq8CckAGBFdM7pHfUlHagMnkENIP3ebZjvaTKtJSbo0dzmkzyYJ26k2w
Example
Finally, let's test our deployed RAG system with some example data. We'll send a query to the RAG interface and observe the generated response. This test will validate the end-to-end functionality of our pipeline and demonstrate the power of the RAG model in action and compare it with how the model would perform without the RAG setup.
data = [
"Covalent is developed and maintained by Agnostiq.",
"Agnostiq was founded in Toronto, Canada.",
"Only one employee at Agnostiq has a moustache.",
"Users should pip-install covalent-cloud to obtain the Covalent SDK",
"Develop, deploy, and scale AI easier than ever with the Covalent compute orchestration platform",
"Easily scale AI deployments with dynamic resource allocation",
]
rag_client.ingest_data(data=data)
print(rag_client.query_llama(prompt="What is Covalent?"))
According to the provided data, Covalent is developed and maintained by Agnostiq, and to obtain the Covalent SDK, you should pip-install covalent-cloud.
# Compare to non RAG case
print(rag_client.query_llama(prompt="What is Covalent?", retrieve=False))
In chemistry, a covalent bond is a chemical bond that forms between two atoms by sharing one or more pairs of electrons. This sharing of electrons creates a strong chemical force that holds the atoms together.
In a covalent bond, each atom contributes one or more electrons to the bond. These electrons are shared equally between the two atoms, resulting in a stable chemical structure. The sharing of electrons is often referred to as "electronic pairing" or "electronic sharing."
Covalent bonds are typically found in molecules, which are collections of atoms that are held together by covalent bonds. Molecules can range in size from simple diatomic molecules like hydrogen chloride (HCl) to complex biological molecules like proteins and nucleic acids.
Some key characteristics of covalent bonds include:
1. **Sharing of electrons**: Covalent bonds involve the sharing of electrons between atoms.
2. **Weak or strong**: Covalent bonds can be either weak or strong, depending on the number of electrons shared and the distance between the atoms.
3. **Directional**: Covalent bonds can have a directional component, meaning that the sharing of electrons is not always symmetrical between the two atoms.
4. **Type**: There are different types of covalent bonds, such as:
* Single covalent bonds: One pair of electrons is shared between atoms.
* Double covalent bonds: Two pairs of electrons are shared between atoms.
* Triple covalent bonds: Three pairs of electrons are shared between atoms.
Covalent bonds are essential for the structure and function of molecules in living organisms and are a fundamental aspect of chemistry.
This test demonstrates the power of our RAG system. By ingesting some sample data and then querying the system, we can see how the RAG pipeline leverages the stored information to generate more informed responses compared to the non-RAG case.
By leveraging Covalent's orchestration capabilities, we've created a flexible and scalable system that can be easily adapted for various AI applications. This RAG pipeline can be extended to handle larger datasets, fine-tuned for specific domains, or integrated with other AI services to create even more powerful applications. We encourage you to explore further possibilities with this setup, such as experimenting with different models, expanding the data sources, or integrating additional services to enhance your AI workflows. The combination of Covalent, NVIDIA NIMs, and Snowflake provides a robust foundation for building advanced, production-ready AI systems.