Build your own synthetic data generator with foundation models
In the competitive world of machine learning, the quality and quantity of training data often dictate the success of a models. However, acquiring vast amounts of labeled data is both costly and time-consuming. Imagine generating millions of high-quality synthetic data samples for just a few bucks—this is the power of leveraging foundation models with Covalent Cloud.
In this tutorial, we will demonstrate how to generate 10,000 synthetic data samples for as little as 50 cents within minutes. We will use Llama 3 8 Billion as the foundation models to generate synthetic data.
Why Synthetic Data?
Synthetic data generation is a powerful tool for various reasons:
Cost-Effectiveness: It significantly reduces the cost of data collection and labeling. Speed: Large datasets can be generated in minutes, accelerating the models development process. Flexibility: Tailor-made datasets can be created to fit specific needs, enhancing models performance.
Step 1: Setting Up the Environment
Covalent Cloud simplifies setting up the computational environment, allowing you to choose the appropriate hardware based on cost and speed. For this tutorial, we'll use a powerful A100 GPU to ensure rapid data generation. We will create an environment directly via python in covalent cloud with required dependencies. Learn more about creating envs here.
import covalent_cloud as cc
# cc.save_api_key("YOUR-API-KEY")
cc.create_env(
name="vllm",
pip=["vllm==0.5.1", "torch==2.3.0"],
wait=True
)
Environment Already Exists.
We will then create the executor, that defines the compute resources and the environment to run the code. This decides the cost and speed of data generation. Here we will use the A100 GPUs.
executor = cc.CloudExecutor(
env="vllm",
num_cpus=4,
num_gpus=1,
memory="100GB",
gpu_type=cc.cloud_executor.GPU_TYPE.A100,
time_limit="in 2 hours",
)
Step 2: Defining the Data Generation Function
The core of our tutorial is a function that uses a foundation models to generate synthetic data based on a specified task. This function refines the input prompt and generates data in batches, ensuring quality and consistency. We need to use the Open-Source covalent to create tasks (@ct.electron) and workflows (@ct.lattice) primitives to create the data generation pipeline. You can install the covalent library using pip install covalent -U.
Note that in here we are downloading the models each and everytime, which is not ideal and one can further optimize cost and runtime by downloading the models once to our distributed shared volume and just reusing it.
import covalent as ct # Open source covalent is used for defining the tasks and workflow
@ct.electron(executor=executor)
def make_datasets(
task,
example="No example provided, please generate based on task.",
format="",
n_data=5,
model="unsloth/llama-3-8b-Instruct",
):
from vllm import LLM, SamplingParams
import random
# Define how many entries are generated in one call to the model.
chunk_size = 10
llm_instance = LLM(
model=model,
trust_remote_code=True,
enforce_eager=True,
)
def generate_data_batch(task, example, format, total_required):
"""Generate data using the LLM models with specific parameters."""
prompt_format = f"Format: {format}\n" if format != "json" else ""
system_prompt = f"You are a helpful and knowledgeable data generating assistant. Your task is to generate {chunk_size} data items for the following task:
{task}. Use the given example and format as guidance if they are given, if not given come up with your own example that suites the given task and a
format that is best. Generate data in the requested format line by line. Make you only give me back the generated data and nothing else before or after
it."
full_prompt = f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
Random seed:{random.randint(0,1000)}
Example: {example}
{prompt_format}
# Make you only give me back the generated data and nothing else before or after it.<|eot_id|><|start_header_id|>assistant<|end_header_id|>"""
num_prompts = (total_required + chunk_size - 1) // chunk_size
generating_prompts = [full_prompt for _ in range(num_prompts)]
sampling_params = SamplingParams(
temperature=0.7, top_p=0.8, max_tokens=1500)
responses = llm_instance.generate(
generating_prompts, sampling_params
) # Process prompts in batch.
all_data = []
for response in responses:
generated_texts = response.outputs[0].text.strip().split("\n")
filtered_texts = [
text for text in generated_texts if len(text) >= 10
] # throw away short text which are junk
all_data.extend(filtered_texts)
return all_data
def generate_data_until_complete(task, example, format, n_data):
"""Generate data repeatedly until the required number of data items is obtained."""
all_data = []
while len(all_data) < n_data:
needed_data = n_data - len(all_data)
data_chunk = generate_data_batch(
task, example, format, needed_data)
all_data.extend(data_chunk)
if len(all_data) >= n_data:
all_data = all_data[:n_data]
break
return all_data
return generate_data_until_complete(task, example, format, n_data)
@ct.lattice(
executor=executor,
workflow_executor=cc.CloudExecutor(
env="vllm", num_cpus=2, num_gpus=0, memory="30GB"
),
)
def generate_data_workflow(
task,
example="No example provided, please generate based on task.",
format="",
n_data=5,
model="unsloth/llama-3-8b-Instruct",
):
return make_datasets(task, example, format, n_data, model)
Step 3: Deploying the Data Generation Workflow
We will create a workflow to dispatch our data generation function on Covalent Cloud, whenever we need new data via
task = """You are a highly qualified expert trained to annotate machine learning training data. Your task is to generate long financial texts and
provide the sentiment of it as positive, negative or neutral and then reason about the label. Base your label decision only on the TEXT and do not speculate e.g.
based on prior knowledge about a company. You first reason step by step about the correct label and then return your label.
"""
example = "Operating profit increased, from EUR 7m to 9m compared to the previous reporting period. (some other long text) # positive # The text mentions an increase in operating profit, which is a positive sign for the company."
format = "text: 'text' # label: positive, negative or neutral # reason: "
n_data = 10_000
run_id = cc.dispatch(generate_data_workflow)(task=task,example=example,format=format, n_data=n_data)
Samples of generated data
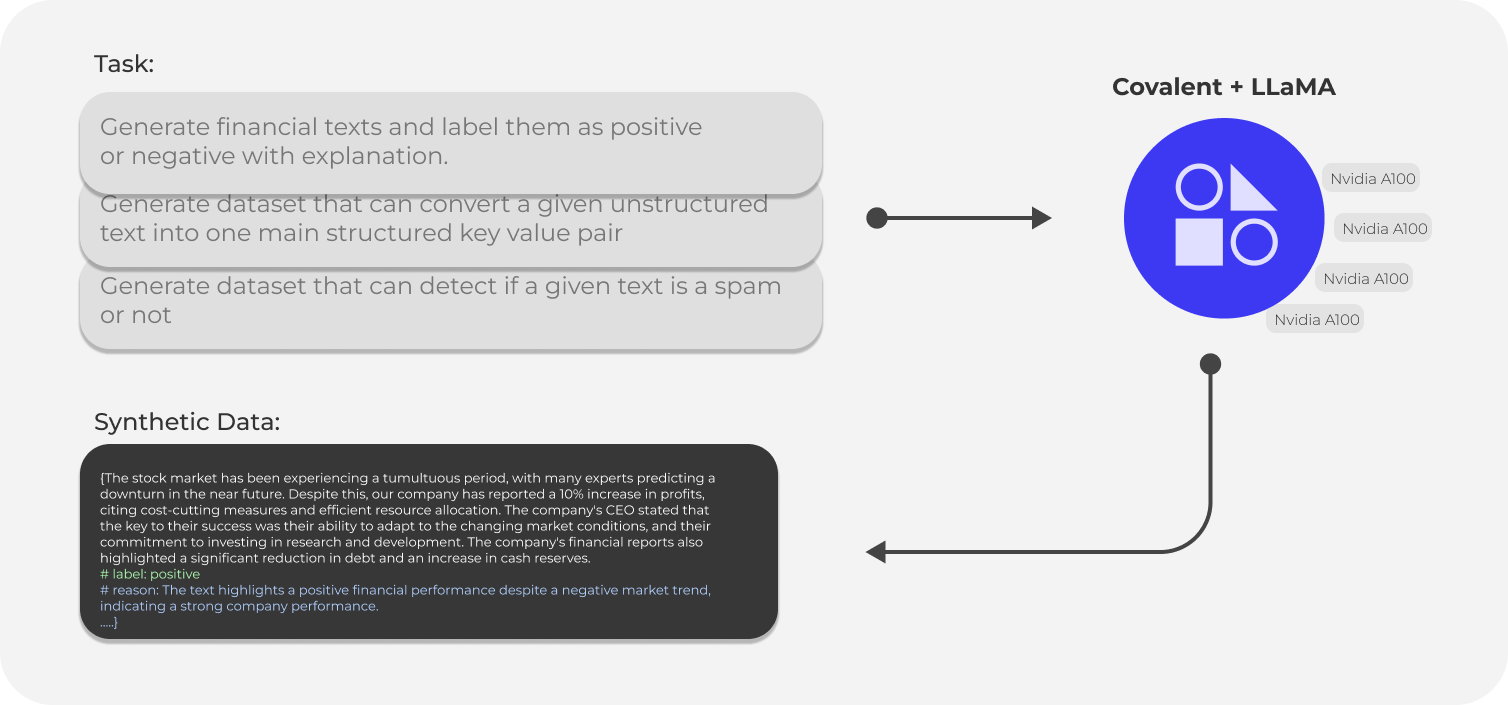
To demonstrate the practical applications and power of synthetic data generation, we will generate 30,000 data samples, split across three distinct use cases. Each use case highlights the flexibility and capability of Covalent Cloud to orchestrate these compute jobs. We will generate 10,000 samples for each task, showcasing how easy it is to create large datasets for various machine learning applications.
1. Financial Sentiment Analysis:
Task: "Generate financial texts and label them as positive or negative with explanation. Give it in the format of text: 'text' # label: positive, negative or neutral # reason:"
This use case is crucial for training sentiment analysis models in the financial domain. By generating labeled financial texts, we can create a robust dataset for training models that need to understand and classify financial sentiments accurately.
2. Unstructured Text to Key-Value Conversion:
Task: "Generate a dataset that can convert a given unstructured text into one main structured key-value pair. It should be in the format of - unstructured text # key-value."
This task demonstrates the ability to convert unstructured text into structured key-value pairs. This is essential for building models that need to extract structured information from raw text, such as entity extraction and information retrieval systems.
3. Spam Detection:
Task: "Generate a dataset that can detect if a given text is a spam or not. It should be in the format of - text # spam or not."
This example highlights the importance of detecting spam in text data. By generating such data, we can train models to accurately identify and filter out spam, improving the efficiency and security of text communication systems.
tasks = [
"""You are a highly qualified expert trained to annotate machine learning training data. Your task is to generate long financial texts covering a variety of
financial events, including earnings reports, market trends, mergers, acquisitions, and other significant financial news. For each text, provide the
sentiment as positive, negative, or neutral, and then reason about the label. Base your label decision only on the TEXT and do not speculate e.g., based on
prior knowledge about a company. You first reason step by step about the correct label and then return your label.""",
"""You are a highly qualified expert trained to annotate machine learning training data. Your task is to convert given unstructured texts into one main
structured key-value pair. The unstructured texts should cover a diverse range of topics such as events, product launches, announcements, and more. Ensure
the key and value accurately reflect the content of the unstructured text. Your response should provide useful information extraction that can be used to
create structured datasets.""",
"""You are a highly qualified expert trained to annotate machine learning training data. Your task is to generate texts that vary widely in style and
content, including promotional messages, notifications, personal messages, and more. Determine if each text is spam or not. Provide a clear indication of
whether the text is spam or not, based on common spam characteristics such as unsolicited messages, suspicious links, and offers that seem too good to be
true."""
]
examples = [
"Operating profit increased, from EUR 7m to 9m compared to the previous reporting period. (some other long text) # positive # The text mentions an increase in operating profit, which is a positive sign for the company.\n",
"The new product launch is scheduled for next month. # key-value: {'product_launch': 'next month'}\n",
"Congratulations! You've won a free ticket to the Bahamas. Click here to claim now. # spam # The text is an unsolicited message with a call to action, typical of spam.\n"
]
formats = [
"text: 'text' # label: positive, negative or neutral # reason: ",
"unstructured text: 'text' # key-value: 'key-value' ",
"text: 'text' # spam or not spam # reason"
]
n_data = 10_000
run_ids = []
for task,example,format in zip(tasks,examples,formats):
run_ids.append(cc.dispatch(generate_data_workflow)(task=task,example=example,format=format, n_data=n_data))
We will query the results, note since we submitted all the dispatches in parallel, the total time for generating all these data is the maximum time taken by any of the dispatches.
data=[]
time_taken=[]
for run_id in run_ids:
result=cc.get_result(run_id,wait=True)
result.result.load()
time_taken.append(result.end_time-result.start_time)
data.append(result.result.value)
print(f"Total wall time taken for generating 30K data points in minutes : {(max(time_taken)).seconds/60:.2f} minutes")
Total wall time taken for generating 30K data points in minutes : 10.87 minutes
Each workflow costed us roughly 50 cents, and took around 10 minutes to generate 10,000 samples. Lets look at the generated examples
from IPython.display import display, HTML
def showcase_data(data, tasks):
content_html = """
"""
content_html += 'Generated Synthetic Data Examples'
for task, examples in zip(tasks, data):
tmp_task = task.split("\n")[0]
content_html += f'Task:{tmp_task}'
for i, example in enumerate(examples[:7], start=1):
content_html += f'Example {i}: {example}'
content_html += "...."
display(HTML(content_html))
showcase_data(data, tasks)
Generated Synthetic Data Examples
Task:
You are a highly qualified expert trained to annotate machine learning training data. Your task is to generate long financial texts covering a variety of financial events, including earnings reports, market trends, mergers, acquisitions, and other significant financial news. For each text, provide the sentiment as positive, negative, or neutral, and then reason about the label. Base your label decision only on the TEXT and do not speculate e.g., based on prior knowledge about a company. You first reason step by step about the correct label and then return your label.
Example 1: text: The company reported a net income of $1.2 billion, a 25% increase from the same period last year. # label: positive # reason: The text mentions a significant increase in net income, which is a positive indicator for the company's financial performance.
Example 2: text: The company's revenue has decreased by 10% year-over-year, citing increased competition in the market. # label: negative # reason: The text mentions a decrease in revenue, which is a negative sign for the company's financial performance.
Example 3: text: The company's stock price surged 15% after announcing a new partnership with a major technology firm. # label: positive # reason: The text mentions an increase in the company's stock price, which is a positive indicator of market sentiment.
Example 4: text: The company's CEO announced his resignation, citing personal reasons. # label: neutral # reason: The text does not mention any specific financial information, so it is neutral in terms of sentiment.
Example 5: text: The company reported a loss of $500 million in the last quarter, citing high operating expenses. # label: negative # reason: The text mentions a loss, which is a negative sign for the company's financial performance.
Example 6: text: The company's revenue has increased by 20% year-over-year, driven by strong demand for its products. # label: positive # reason: The text mentions an increase in revenue, which is a positive sign for the company's financial performance.
Example 7: text: The company's board of directors has approved a new share buyback program. # label: positive # reason: The text mentions a potential increase in shareholder value, which is a positive sign for the company.
...
Task:
You are a highly qualified expert trained to annotate machine learning training data. Your task is to convert given unstructured texts into one main
structured key-value pair. The unstructured texts should cover a diverse range of topics such as events, product launches, announcements, and more. Ensure the
key and value accurately reflect the content of the unstructured text. Your response should provide useful information extraction that can be used to create
structured datasets.
Example 1: The new product launch is scheduled for next month. # key-value: {'product_launch': 'next month'}
Example 2: The company has announced a new partnership with a leading tech firm. # key-value: {'partnership': 'leading tech firm'}
Example 3: The annual music festival is taking place on July 15th. # key-value: {'music_festival': 'July 15th'}
Example 4: The company is planning to expand its operations to Asia. # key-value: {'expansion': 'Asia'}
Example 5: The new policy aims to reduce carbon emissions by 20%. # key-value: {'carbon_reduction': '20%'}
Example 6: The popular social media platform has reached 1 billion users. # key-value: {'user_base': '1 billion'}
Example 7: The new restaurant is offering a special promotion for the summer. # key-value: {'promotion': 'summer'}
...
Task:
You are a highly qualified expert trained to annotate machine learning training data. Your task is to generate texts that vary widely in style and content,
including promotional messages, notifications, personal messages, and more. Determine if each text is spam or not. Provide a clear indication of whether the text
is spam or not, based on common spam characteristics such as unsolicited messages, suspicious links, and offers that seem too good to be true.
Example 1: Here is the generated data:
Example 2: "Congratulations! You've been selected for a special promotion! Click here to redeem your exclusive offer. # spam # Unsolicited message with a call to action"
Example 3: "Hello, I'm John, your old friend! I've been thinking about you lately and wanted to catch up. Let's grab coffee soon? # not spam # Personal message"
Example 4: "Get the latest smartphone at an unbeatable price! Limited time offer, don't miss out! # spam # Suspicious offer with a sense of urgency"
Example 5: "Hi, this is a reminder that your subscription to our newsletter is about to expire. Please confirm your subscription to continue receiving updates. # not spam # Notification"
Example 6: "Make money from home with our easy-to-use app! Sign up now and start earning today! # spam # Unsolicited message with a promise of easy money"
Example 7: "Happy birthday! We're celebrating with a special discount on our best-selling products. Use code BIRTHDAY15 at checkout. # not spam # Personalized message with a promotion"
...
Ofcourse note that based on the task and the models used, the cost and time and quality can vary, one can play around with the prompt, the models and the hyperparameters to get the desired quality and quantity of data, and even add post cleaning steps to further refine the data or add agents to further enhance the data quality check.
Conclusion
In this tutorial, we've demonstrated how easy it is to generate synthetic data using foundation models on Covalent Cloud. With minimal setup and code, you can produce large datasets quickly and affordably, enabling you to train smaller models efficiently. The flexibility to choose different models and hardware based on cost and speed makes this approach highly adaptable to various needs. One can further optimize this setup for various use cases with multi agent quality assessment to more polished example generation using larger models like from OpenAI's. By leveraging Covalent Cloud, you can focus on developing innovative machine learning applications without worrying about the complexities of infrastructure management, especially at scale.